Assume I have the following dataframe in Python:
A = [['A',2,3],['A',5,4],['B',8,9],['C',8,10],['C',9,20],['C',10,20]]
B = pd.DataFrame(A, columns = ['Col1','Col2','Col3'])
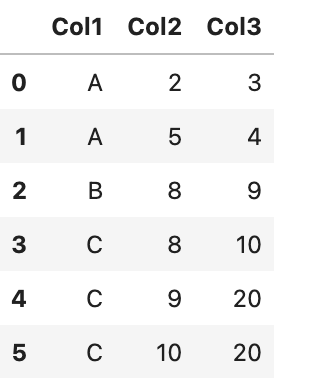
This gives me the above dataframe: I want to remove the rows that have the same values for Col1 but different values for Col3. I have tried to use drop_duplicates command with different subset of columns but it does not give what I want. I can write for loop but that is not efficient at all (since you might have much more columns than this).
C= B.drop_duplicates(['Col1','Col3'],keep = False)
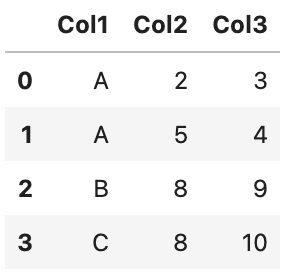
Can anyone help if there is any command in Python can do this without using for loop?
CodePudding user response:
This can do the job,
grouped_df = df.groupby(["Col1"])
groups = []
for group in df["Col1"].unique():
group_df = grouped_df.get_group(group)
groups.append(group_df.loc[group_df["Col3"].drop_duplicates(keep = False).index])
new_df = pd.concat(groups)
Output -
| Col1 | Col2 | Col3 | |
|---|---|---|---|
| 0 | A | 2 | 3 |
| 1 | A | 5 | 4 |
| 2 | B | 8 | 9 |
| 3 | C | 8 | 10 |
CodePudding user response:
Use:
A = [['A',2,3],['A',5,4],['B',8,9],['C',8,10],['C',9,20],['C',10,20]]
B = pd.DataFrame(A, columns = ['Col1','Col2','Col3'])
#Solution
B[B.groupby('Col1')['Col3'].transform(lambda x: x.drop_duplicates(keep=False))>0]
Output:
Col1 Col2 Col3
0 A 2 3
1 A 5 4
2 B 8 9
3 C 8 10
Also, you can use:
B[B.groupby('Col1')['Col3'].transform(lambda x: x.drop_duplicates(keep=False)).notna()]
CodePudding user response:
A = [['A',2,3],['A',5,4],['B',8,9],['C',8,10],['C',9,20],['C',10,20]]
df = pd.DataFrame(A, columns = ['Col1','Col2','Col3'])
output = df[~df[['Col1', 'Col3']].duplicated(keep=False)]
print(output)
Output:
Col1 Col2 Col3
0 A 2 3
1 A 5 4
2 B 8 9
3 C 8 10