I have a dataframe which needs to be consolidated for same ids and split other columns to different columns as such. I have presented the example input dataframe and required output dataframe.
Input dataframe example
data = {'id':[1, 1, 1, 2, 2, 2],
'status':[3, 3, 3, 4, 4, 4],
'amount':[30, 40, 50, 60, 70, 80],
'paid':[100, 200, 300, 400, 500, 600]}
dataframe = pd.DataFrame(data)
id status amount paid
0 1 3 30 100
1 1 3 40 200
2 1 3 50 300
3 2 4 60 400
4 2 4 70 500
5 2 4 80 600
Required output dataframe
id status amount_1 amount_2 amount_3 paid_1 paid_2 paid_3
0 1 3 30 40 50 100 200 300
1 2 4 60 70 80 300 400 600
CodePudding user response:
Does the following achieve what you are after?
Reproduce your example
import pandas as pd
import numpy as np
data = {'id':[1, 1, 1, 2, 2, 2],
'status':[3, 3, 3, 4, 4, 4],
'amount':[30, 40, 50, 60, 70, 80],
'paid':[100, 200, 300, 400, 500, 600]}
dataframe = pd.DataFrame(data)
output:
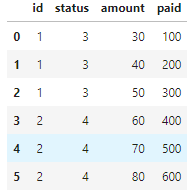
Step 1: Create index within each group, and set index of dataframe
dataframe['group_id'] = dataframe.groupby('id')['id'].transform(lambda x: np.arange(1,len(x) 1))
dataframe.set_index(['id', 'group_id'], append=False, inplace=True)
Now the dataframe looks like:
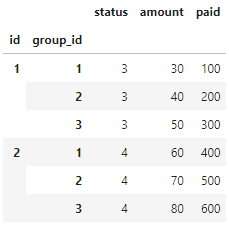
Step 3: Unstack on the group index
dataframe = dataframe.unstack(level=-1)
Now the dataframe looks like:
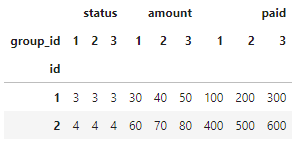
Final step: Flatten the column names to match your desired output, and drop extra status columns
dataframe.columns = [f"{x}_{y}" for x,y in dataframe.columns]
dataframe.drop(['status_2', 'status_3'], axis=1, inplace=True)
dataframe.rename({'status_1': 'status'}, axis=1, inplace=True)
Giving final form:
