I have this dataframe:
df = pd.DataFrame({'Position1':[1,2,3], 'Count1':[55,35,45],\
'Position2':[4,2,7], 'Count2':[15,35,75],\
'Position3':[3,5,6], 'Count3':[45,95,105]})
print(df)
Position1 Count1 Position2 Count2 Position3 Count3
0 1 55 4 15 3 45
1 2 35 2 35 5 95
2 3 45 7 75 6 105
I want to join the Position columns into one column named "Positions" while sorting the data in the Counts columns like so:
Positions Count1 Count2 Count3
0 1 55 Nan Nan
1 2 35 35 Nan
2 3 45 NaN 45
3 4 NaN 15 Nan
4 5 NaN NaN 95
5 6 Nan NaN 105
6 7 Nan 75 NaN
I've tried melting the dataframe, combining and merging columns but I am a bit stuck.
Note that the NaN types can easily be replaced by using df.fillna to get a dataframe like so:
df = df.fillna(0)
Positions Count1 Count2 Count3
0 1 55 0 0
1 2 35 35 0
2 3 45 0 45
3 4 0 15 0
4 5 0 0 95
5 6 0 0 105
6 7 0 75 0
CodePudding user response:
Does this achieve what you are after?
import pandas as pd
df = pd.DataFrame({'Position1':[1,2,3], 'Count1':[55,35,45],\
'Position2':[4,2,7], 'Count2':[15,35,75],\
'Position3':[3,5,6], 'Count3':[45,95,105]})
df1, df2, df3 = df.iloc[:,:2], df.iloc[:, 2:4], df.iloc[:, 4:6]
df1.columns, df2.columns, df3.columns = ['Positions', 'Count1'], ['Positions', 'Count2'], ['Positions', 'Count3']
df1.merge(df2, on='Positions', how='outer').merge(df3, on='Positions', how='outer').sort_values('Positions')
Output:
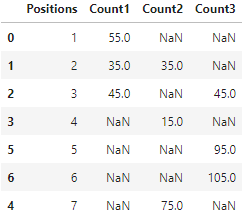
CodePudding user response:
wide_to_long unpivots the DF from Long to wide and that is what's used here.
columns names are also renamed here, with this edit
df['id'] = df.index
df2=pd.wide_to_long(df, stubnames=['Position','Count'], i='id', j='pos').reset_index()
df2=df2.pivot(index=['id','Position'], columns='pos', values='Count').reset_index().fillna(0).add_prefix('count_')
df2.rename(columns={'count_id': 'id', 'count_Position' :'Position'}, inplace=True)
df2
RESULT:
pos id Position 1 2 3
0 0 1 55.0 0.0 0.0
1 0 3 0.0 0.0 45.0
2 0 4 0.0 15.0 0.0
3 1 2 35.0 35.0 0.0
4 1 5 0.0 0.0 95.0
5 2 3 45.0 0.0 0.0
6 2 6 0.0 0.0 105.0
7 2 7 0.0 75.0 0.0
PS: I'm unable to format the output, I'll appreciate if someone guide me here. Thanks!
CodePudding user response:
Here is a way to do what you've asked:
df = df[['Position1', 'Count1']].rename(columns={'Position1':'Positions'}).join(
df[['Position2', 'Count2']].set_index('Position2'), on='Positions', how='outer').join(
df[['Position3', 'Count3']].set_index('Position3'), on='Positions', how='outer').sort_values(
by=['Positions']).reset_index(drop=True)
Output:
Positions Count1 Count2 Count3
0 1 55.0 NaN NaN
1 2 35.0 35.0 NaN
2 3 45.0 NaN 45.0
3 4 NaN 15.0 NaN
4 5 NaN NaN 95.0
5 6 NaN NaN 105.0
6 7 NaN 75.0 NaN
Explanation:
- Use
joinfirst onPosition1, Count1andPosition2, Count2(withPosition1renamed asPositions) then on that join result andPosition3, Count3. - Sort by
Positionsand usereset_indexto create a new integer range index (ascending with no gaps).