I have three pandas Series, called: Col_data, C_PV_data and C_elec_data. Each one has these values:
Col_data:
0 625814.205486
1 782267.756857
2 938721.308229
Name: 7, dtype: object
C_PV_data:
0 2039032.206909
1 2548790.258636
2 3058548.310363
Name: 3, dtype: object
C_elec_data:
0 1337523.743009
1 1671904.678761
2 2006285.614513
Name: 0, dtype: object
I would like to aggregate them into a single DataFrame, to export that DataFrame to a .xlsx file, in which each column is called as the variable. For instance:
| Col_data | C_PV_data | C_elec_data |
|---|---|---|
| 625814.205486 | 2039032.206909 | 1337523.743009 |
| 782267.756857 | 2548790.258636 | 1671904.678761 |
| 938721.308229 | 3058548.310363 | 2006285.614513 |
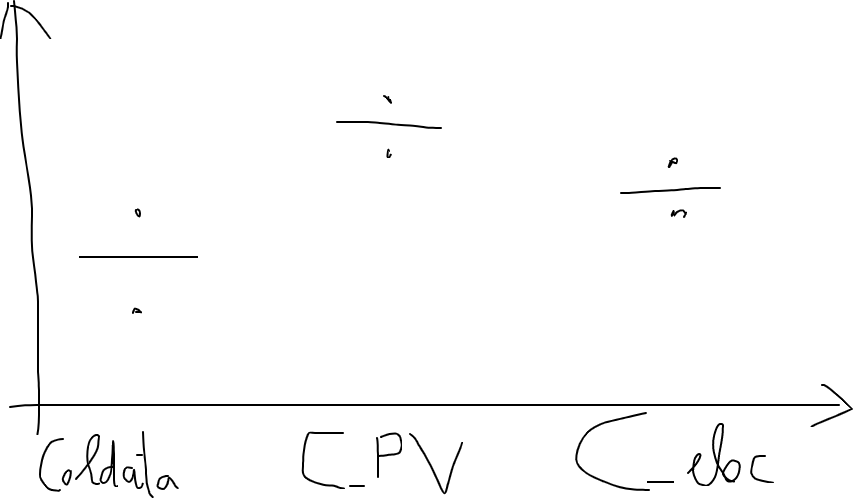
Finally, I would like to represent each column with a graph in which the central value is a line, and two dots over that line, for the lowest and hights value. For instance, the graph would be something like this:
CodePudding user response:
Sure, here you go:
Init
Col_data = pd.Series([
625814.205486,
782267.756857,
938721.308229])
C_PV_data = pd.Series([
2039032.206909,
2548790.258636,
3058548.310363])
C_elec_data = pd.Series([
1337523.743009,
1671904.678761,
2006285.614513])
As a df
df = pd.concat(
[Col_data, C_PV_data, C_elec_data], axis=1,
keys=['Col_data', 'C_PV_data', 'C_elec_data'])
>>> df
Col_data C_PV_data C_elec_data
0 625814.205486 2.039032e 06 1.337524e 06
1 782267.756857 2.548790e 06 1.671905e 06
2 938721.308229 3.058548e 06 2.006286e 06
Side note: I always dislike repeats. The following alternative to the above is DRY (Don't Repeat Yourself), but less clear perhaps:
keys = ['Col_data', 'C_PV_data', 'C_elec_data']
d = locals() # just for DRY...
df = pd.concat([d[k] for k in keys], axis=1, keys=keys)
To xlsx
Assuming you have openpyxl installed:
df.to_excel('foo.xlsx', index=False)
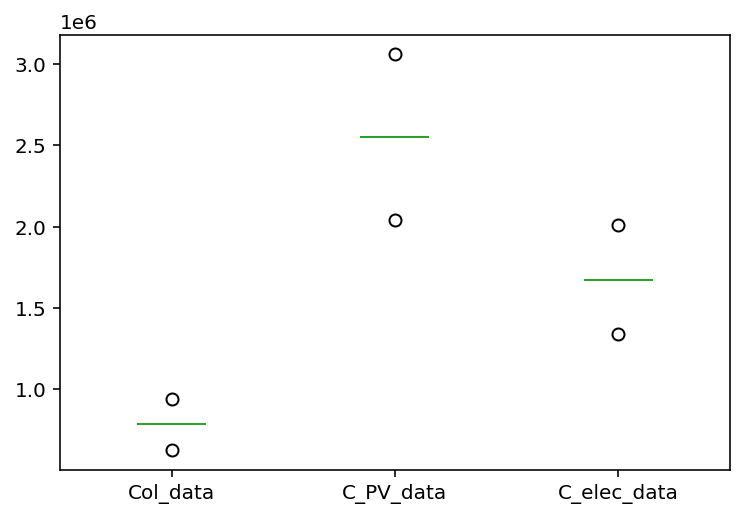
Box plot
df.loc[[0,1,1,1,2]].plot.box()