I am in need of a way to devise a column (data_sequence) that uses the following logic as based off values in other columns (col_1:col_5).
The column elements in col_1:col_5 contain both 1) values and 2) NA entries.
The flow of construction of the 'data_sequence' column moves from right to left within col_1:col_5 .
Initially, 'data_sequence' assumes the values of the rightmost column (col_5) until the first instance of NA is hit in that column.
col_4 then becomes the relevant column upon which to harvest data. col_4 values are then assumed for 'data_sequence' in corresponding rows until its first instance of NA appears.
The process continues through col_1, at which point 'data_sequence' is fully populated with the appropriate values.
The values present in col_1:col_5 stair-step downward from right to left as this sample data indicates. That is, values in adjacent columns may begin in the same row, but values never begin at a lower row value in the left column of any adjacent pair of columns.
Once 'data_sequence' is populated, I also need a column (column_offset) that provides the column offset relative to the first column (row).
Any solutions, elegant or otherwise, are greatly appreciated.
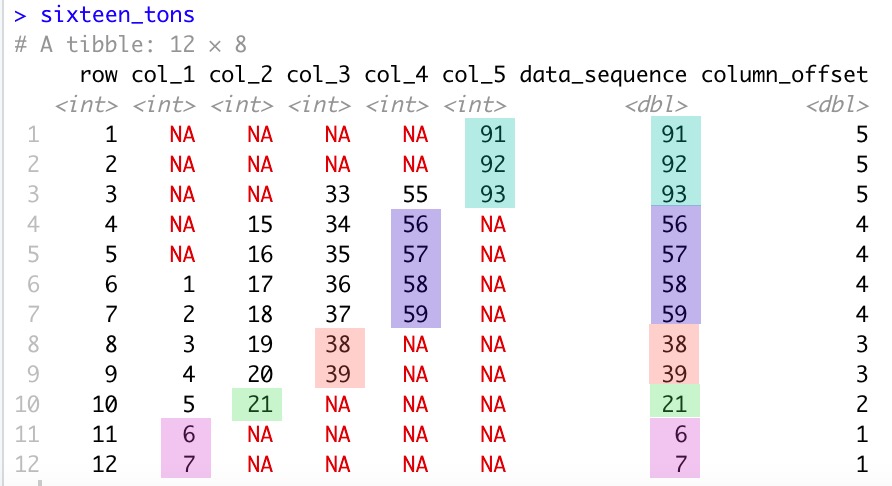
sixteen_tons <- tibble(row = 1:12,
col_1 = c( rep(NA, 5), 1:7),
col_2 = c( rep(NA, 3) , 15:21, rep(NA, 2) ),
col_3 = c( rep(NA, 2) , 33:39, rep(NA, 3) ),
col_4 = c( rep(NA, 2) , 55:59, rep(NA, 5) ),
col_5 = c( 91:93, rep(NA, 9) ),
data_sequence = c(91:93, 56:59, 38:39, 21, 6:7),
column_offset = c(rep(5,3), rep(4,4), rep(3,2), rep(2,1), rep(1,2) )
)
CodePudding user response:
We could use coalesce with max.col
library(dplyr)
library(purrr)
sixteen_tons %>%
mutate(data_sequence2 = invoke(coalesce,
rev(across(starts_with('col_')))),
column_offset2 = max.col(!is.na(across(starts_with('col_'))), 'last'))
-output
# A tibble: 12 × 10
row col_1 col_2 col_3 col_4 col_5 data_sequence column_offset data_sequence2 column_offset2
<int> <int> <int> <int> <int> <int> <dbl> <dbl> <int> <int>
1 1 NA NA NA NA 91 91 5 91 5
2 2 NA NA NA NA 92 92 5 92 5
3 3 NA NA 33 55 93 93 5 93 5
4 4 NA 15 34 56 NA 56 4 56 4
5 5 NA 16 35 57 NA 57 4 57 4
6 6 1 17 36 58 NA 58 4 58 4
7 7 2 18 37 59 NA 59 4 59 4
8 8 3 19 38 NA NA 38 3 38 3
9 9 4 20 39 NA NA 39 3 39 3
10 10 5 21 NA NA NA 21 2 21 2
11 11 6 NA NA NA NA 6 1 6 1
12 12 7 NA NA NA NA 7 1 7 1