I have a simple df as below, and I would like to create a summary notation for it. what will be the most effective way to build it? Could anyone guide me on this?
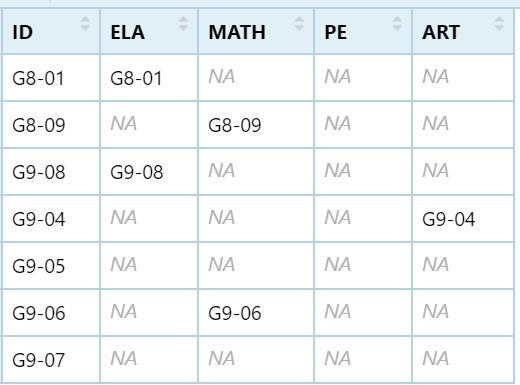
The summary that I would like to build is:
There are 2 students in ELA: G8-01, G9-08; There are 2 students in MATH: G8-09, G9-06; There is 1 student in ART: G9-04.
structure(list(ID = c("G8-01", "G8-09", "G9-08", "G9-04", "G9-05",
"G9-06", "G9-07"), ELA = c("G8-01", NA, "G9-08", NA, NA, NA,
NA), MATH = c(NA, "G8-09", NA, NA, NA, "G9-06", NA), PE = c(NA,
NA, NA, NA, NA, NA, NA), ART = c(NA, NA, NA, "G9-04", NA, NA,
NA)), row.names = c(NA, -7L), class = c("tbl_df", "tbl", "data.frame"))
CodePudding user response:
A tidyverse solution using stringr::str_glue_data() to format a string:
library(tidyverse)
df %>%
pivot_longer(-1, values_drop_na = TRUE) %>%
group_by(name) %>%
summarise(n = n(), id = toString(value)) %>%
str_glue_data("There {ifelse(n>1, 'are', 'is')} {n} student{ifelse(n>1, 's', '')} in {name}: {id};")
which returns
# There is 1 student in ART: G9-04;
# There are 2 students in ELA: G8-01, G9-08;
# There are 2 students in MATH: G8-09, G9-06;
CodePudding user response:
You would typically do this with cat. You probably want to map the columns and their names together, and for tidiness put it inside a little function:
report <- function(data) {
Map(function(x, nm) {
cat('There are ', sum(!is.na(x)), " students in ", nm, ": ",
paste(x[!is.na(x)], collapse = ', '), '\n', sep = '')
}, x = data[-1], nm = names(data)[-1])
invisible(NULL)
}
This results in:
report(df)
#> There are 2 students in ELA: G8-01, G9-08
#> There are 2 students in MATH: G8-09, G9-06
#> There are 0 students in PE:
#> There are 1 students in ART: G9-04
CodePudding user response:
You can use pluralize() from the package cli.
library(cli)
library(dplyr)
library(purrr)
df %>%
select(-ID) %>%
map(discard, is.na) %>%
compact() %>%
iwalk(~ cat(pluralize("There {qty(length(.x))}{?is/are} {length(.x)} student{?s} in {qty(.y)}{.y}: {qty(.x)}{.x}"), sep = "\n"))
Which gives the following:
There are 2 students in ELA: G8-01 and G9-08
There are 2 students in MATH: G8-09 and G9-06
There is 1 student in ART: G9-04
You can tweak this to return the text if you want to use it elsewhere. I used cat() in this example to just print it to the console.
For example to save the text:
txt <- df %>%
select(-ID) %>%
map(discard, is.na) %>%
compact() %>%
imap_chr(~ pluralize("There {qty(length(.x))}{?is/are} {length(.x)} student{?s} in {qty(.y)}{.y}: {qty(.x)}{.x}"))
unname(txt)
# [1] "There are 2 students in ELA: G8-01 and G9-08"
# [2] "There are 2 students in MATH: G8-09 and G9-06"
# [3] "There is 1 student in ART: G9-04"
CodePudding user response:
The previous answer is already good if you want a report for every subject. If you just want to get automatically the line as you said you can use:
First, create a summary with all the subjects, number students and the codes:
example = example %>%
pivot_longer(cols=c(-ID),names_to='Subject',values_to='Code') %>%
filter(! is.na(Code)) %>%
group_by(Subject) %>%
summarise(n_students = n(),
Codes = paste0(Code, collapse=', '))
Put everything together:
lapply(example,
function(i) paste0(paste("There are",example$n_students,"students in",example$Subject,":",example$Codes),
collapse='; '))[[1]]
Output:
[1] "There are 1 students in ART : G9-04; There are 2 students in ELA : G8-01, G9-08; There are 2 students in MATH : G8-09, G9-06"
Maybe lapply is not the most elegant way, but, it works. Also, you can apply as.factor to Subjects and create the levels to sort the sentence as you want.