driver = webdriver.Chrome()
URL= ['https://makemyhomevn.com/collections/ghe-an-cafe/products/ghe-go-tron']
driver.get(URL)
sleep(1)
des = driver.find_element_by_xpath('//div[@]//strong/following sibling::text()[1]')
print(des)
I expect my result as 'Gỗ tự nhiên', I have tried many ways but couldn't get the text after 'Chất liệu:'.
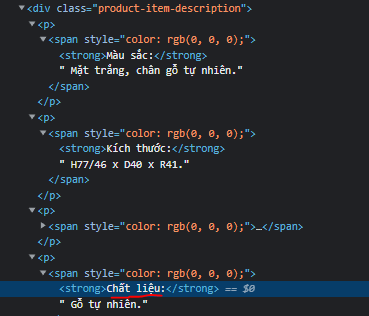
CodePudding user response:
You can take the entire span text using .get_attribute('innerText') and then use the split function from Python like below:
driver.maximize_window()
wait = WebDriverWait(driver, 20)
driver.get("https://makemyhomevn.com/collections/ghe-an-cafe/products/ghe-go-tron")
time.sleep(1)
entire_span = wait.until(EC.visibility_of_element_located((By.XPATH, "//strong[text()='Chất liệu:']/..")))
entire_span_splitted = entire_span.get_attribute('innerText').split(":")
#print(entire_span_splitted[0])
print(entire_span_splitted[1])
Imports:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
Output:
Gỗ tự nhiên.