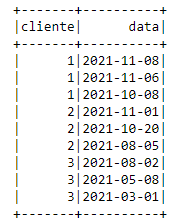
The sample of the dataset I am working on:
data = [(1, "2021-11-08"), (1, "2021-11-06"), (1, "2021-10-08"), (2, "2021-11-01"), (2, "2021-10-20"),
(2, "2021-08-05"), (3, "2021-08-02"), (3, "2021-05-08"), (3, "2021-03-01")]
df = spark.createDataFrame(data=data,schema=columns)
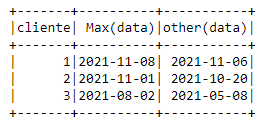
I'd like to take the customer's most recent purchase (the customer's date.max()) and the previous maximum purchase (the penultimate purchase) and take the difference between the two (I'm assuming the same product on all purchases). I still haven't found something in pyspark that does this. One example of my idea was to do this in a groupby, like a below with the minimum date and maximum date.
df1 = df.withColumn('data',to_date(df.data))
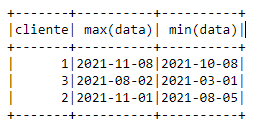
dados_agrupados_item = df1.groupBy(["cliente"]).agg(max("data"), \
min("data"), \
)
The output is:
For my problem, the output would be the maximum date and the penultimate purchase date from that customer. The output should be:
Another method could also be directly delivering the difference between these two dates. But I have no idea how to implement it.
Thank you very much in advance.
CodePudding user response:
Use group by with collect_list to collect all dates per group
Use reverse/array_sort to enforce descending order of the array.
Reference the first and second purchases. (We hope they have purchased twice or we'd need more complex logic to handle it.)
df1.groupBy(["Client"])\
.agg(
reverse( # collect all the dates in an array in descending order from most recent to oldest.
array_sort(
collect_list( df1.data ))).alias("dates") )\
.select(
col("Client"),
col("dates")[0].alias("last_purchase"), # get last purchase
col("dates")[1].alias("penultimate") )\ #get last purchase 1
.show()
------ ------------- -----------
|Client|last_purchase|penultimate|
------ ------------- -----------
| 1| 2021-11-08| 2021-11-06|
| 3| 2021-08-02| 2021-05-08|
| 2| 2021-11-01| 2021-10-20|
------ ------------- -----------