This is the original data and I need the mean of each year of all the variables.
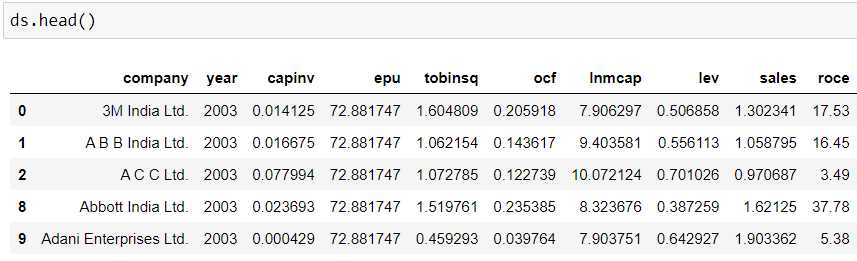
But when I am using groupby('year') command, it is dropping all variables except 'lnmcap' and 'epu'.
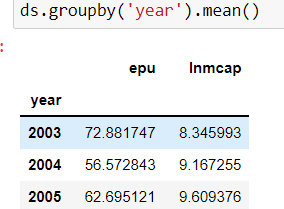
Why this is happening and what needs to be done?
CodePudding user response:
Probably the other columns have object or string type of the data, instead of integer, as a result of which only 'Inmcap' and 'epu' has got the average column.
Use ds.dtypes or simply ds.info() to check the data types of data in the columns
it comes out to be object/string type then use
ds=ds.drop('company',axis=1)
column_names=ds.columns
for i in column_names:
ds[i]=ds[i].astype(str).astype(float)
This could work
CodePudding user response:
You will need to convert the numeric columns to float types. Use df.info() to check the various data types.
for col in ds.select_dtypes(['object']).columns:
try:
ds[col] = ds[col].astype('float')
except:
continue
After this, use df.info() to check again. Those columns with objects like '1.604809' will be converted to float 1.604809
Sometimes, the column may contain some "dirty" data that cannot be converted to float. In this case, you could use below code with errors='coerce' means non-numeric data becomes NaN
ds[col] = pd.to_numeric(ds[col], errors='coerce')