I would like to ask how to join (or merge) multiple dataframes (arbitrary number) whose columns may have the same name. I know this has been asked several times, but could not find a clear answer in any of the questions I have looked at.
import pickle
import os
from posixpath import join
import numpy as np
import pandas as pd
import re
import pickle
np.random.seed(1)
n_cols = 3
col_names = ["Ci"] ["C" str(i) for i in range(n_cols)]
def get_random_df():
values = np.random.randint(0, 10, size=(4,n_cols))
index = np.arange(4).reshape([4,-1])
return pd.DataFrame(np.concatenate([index, values], axis=1), columns=col_names).set_index("Ci")
dfs = []
for i in range(3):
dfs.append(get_random_df())
print(dfs[0])
print(dfs[1])
with output:
C0 C1 C2
Ci
0 5 8 9
1 5 0 0
2 1 7 6
3 9 2 4
C0 C1 C2
Ci
0 5 2 4
1 2 4 7
2 7 9 1
3 7 0 6
If I try and join two dataframes per iteration:
# concanenate two per iteration
df = dfs[0]
for df_ in dfs[1:]:
df = df.join(df_, how="outer", rsuffix="_r")
print("** 1 **")
print(df)
the final dataframe has columns with the same name: for example, C0_r is repeated for each joined dataframe.
** 1 **
C0 C1 C2 C0_r C1_r C2_r C0_r C1_r C2_r
Ci
0 5 8 9 5 2 4 9 9 7
1 5 0 0 2 4 7 6 9 1
2 1 7 6 7 9 1 0 1 8
3 9 2 4 7 0 6 8 3 9
This could be easily solved by providing a different suffix per iteration. However, [the doc on join] says 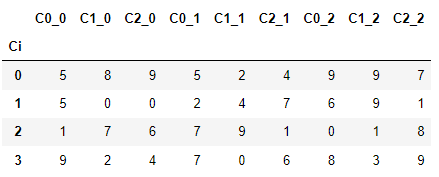
CodePudding user response:
Wouldn't be more readable to display your data like this?
By adding this line of code at the end:
pd.concat([x for x in dfs], axis=1, keys=[f'DF{str(i 1)}' for i in range(len(dfs))])
#output
DF1 DF2 DF3
C0 C1 C2 C0 C1 C2 C0 C1 C2
Ci
0 5 8 9 5 2 4 9 9 7
1 5 0 0 2 4 7 6 9 1
2 1 7 6 7 9 1 0 1 8
3 9 2 4 7 0 6 8 3 9