I have a really huge dataset and I'm looking for the simplest (and fastest) way to create a column that sums the value from one specific column and then proceed to leave only one of the duplicates.
My dataset looks like this:
data <- data.frame(DATE_INTER = c("2015-05-29", "2013-12-13", "2009-09-08"),
DATE_SAIDA = c("2015-06-10", "2013-12-15", "2009-10-20"),
GRUPO_AIH = c("09081997", "13122006", "13122006"),
DIAS_PERMANENCIA = c(12, 2, 42))
I need to use the column "GRUPO_AIH" to check for duplicates. My final output would be something like this:

I've already tried this, but it takes too long and after it's done, I can't even filter anything with dplyr that R stops working.
data <- data %>%
group_by(GRUPO_AIH) %>%
mutate(DIAS_PERMANENCIA2 = sum(DIAS_PERMANENCIA))
Any suggestions?
CodePudding user response:
here is the answer. Just one observation, in your provided dataset example you dont really have any duplicated values in GRUPO_AIH variable so i changed to GRUPO_AIH = c("09081997", "13122006", "13122006"),
data %>%
group_by(GRUPO_AIH) %>%
mutate(DIAS_PERMANENCIA = sum(DIAS_PERMANENCIA)) %>%
filter(duplicated(GRUPO_AIH) == FALSE)
DATE_INTER DATE_SAIDA GRUPO_AIH DIAS_PERMANENCIA
<chr> <chr> <chr> <dbl>
1 2015-05-29 2015-06-10 09081997 12
2 2013-12-13 2013-12-15 13122006 44
OBS: também sou sanitarista atuando com dados na vigilância kk
CodePudding user response:
If you have a "very large dataset" (millions of rows) perhaps this will be fastest:
library(data.table)
data <- data.frame(DATE_INTER = c("2015-05-29", "2013-12-13", "2009-09-08"),
DATE_SAIDA = c("2015-06-10", "2013-12-15", "2009-10-20"),
GRUPO_AIH = c("09081997", "13122206", "13122206"),
DIAS_PERMANENCIA = c(12, 2, 42))
data_dt <- setDT(data)
setkey(data_dt, GRUPO_AIH)
data_dt[, DIAS_PERMANENCIA := sum(DIAS_PERMANENCIA), by = "GRUPO_AIH"]
data_final <- as.data.frame(data_dt[!duplicated(data_dt, by = "GRUPO_AIH")])
data_final
#> DATE_INTER DATE_SAIDA GRUPO_AIH DIAS_PERMANENCIA
#> 1 2015-05-29 2015-06-10 09081997 12
#> 2 2013-12-13 2013-12-15 13122206 44
Created on 2022-05-31 by the 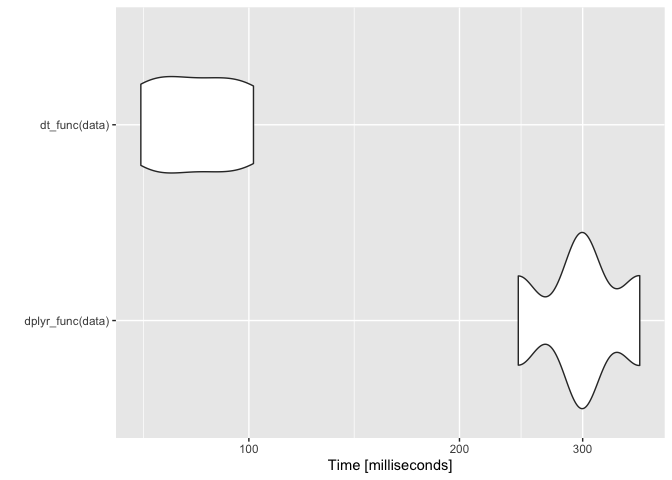
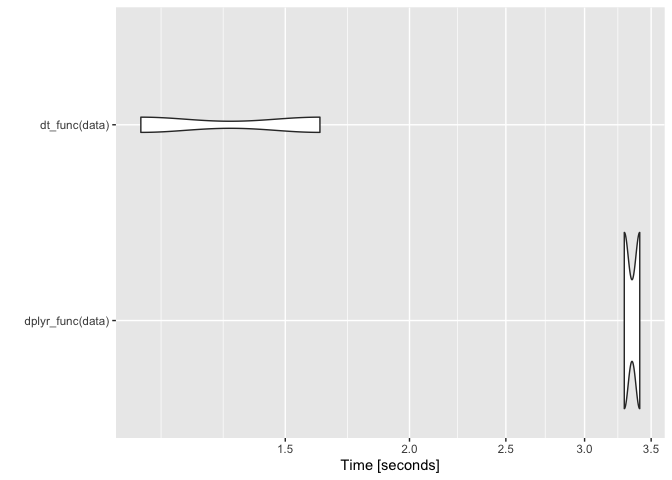
# The difference in speed will likely become more pronounced as the size of the data increases
data <- data.frame(DATE_INTER = rep(c("2015-05-29", "2013-12-13", "2009-09-08"), times = 10e6),
DATE_SAIDA = rep(c("2015-06-10", "2013-12-15", "2009-10-20"), times = 10e6),
GRUPO_AIH = rep(c("09081997", "13122206", "13122206"), times = 10e6),
DIAS_PERMANENCIA = rep(c(12, 2, 42), times = 10e6))
dplyr_func <- function(data){
data_final <- data %>%
dplyr::group_by(GRUPO_AIH) %>%
dplyr::mutate(DIAS_PERMANENCIA = sum(DIAS_PERMANENCIA)) %>%
dplyr::filter(duplicated(GRUPO_AIH) == FALSE)
return(data_final)
}
dt_func <- function(data){
data_dt <- data.table::setDT(data)
data.table::setkey(data_dt, GRUPO_AIH)
data_dt[, DIAS_PERMANENCIA := sum(DIAS_PERMANENCIA), by = "GRUPO_AIH"]
data_final <- as.data.frame(data_dt[!duplicated(data_dt, by = "GRUPO_AIH")])
return(data_final)
}
res <- microbenchmark(dplyr_func(data), dt_func(data), times = 2)
autoplot(res)
#> Coordinate system already present. Adding new coordinate system, which will replace the existing one.
Created on 2022-05-31 by the reprex package (v2.0.1)