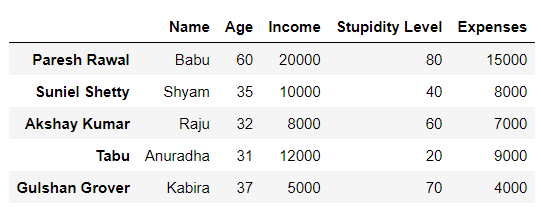
I have the following dataframe.
data = {'Name': ["Babu", "Shyam", "Raju", "Anuradha", "Kabira"],
'Age': [60, 35, 32, 31, 37],
'Income': [20000, 10000, 8000, 12000, 5000],
'Stupidity Level': [80, 40, 60, 20, 70],
'Expenses': [15000,8000,7000,9000,4000]
}
index = ["Paresh Rawal", "Suniel Shetty", "Akshay Kumar","Tabu", "Gulshan Grover"]
df = pd.DataFrame(data, index)
I am trying to find out a row (person) who saves maximum amount every month.
savings = df["Income"] - df["Expenses"]
savings.max()
5000
In this case, it should return the first row whose savings is maximum (5000). But I am trying to this without actually creating a new column for savings. So want to do something like
df[savings.max()] # should return the row with maximum savings.
df[(df["Income"] - df["Expenses"]).max()]
But of course, none of this isn't working. Not sure of the correct synatax.
CodePudding user response:
Use idxmax:
df.loc[df["Income"].sub(df["Expenses"]).idxmax()]
output:
Name Babu
Age 60
Income 20000
Stupidity Level 80
Expenses 15000
Name: Paresh Rawal, dtype: object
all max
s = df["Income"].sub(df["Expenses"])
out = df[s.eq(s.max())]