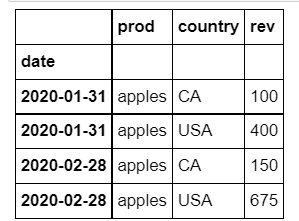
I have the following data:
import pandas as pd
import numpy as np
from numpy import rec, nan
df1=pd.DataFrame.from_records(rec.array([(202001L, 2020L, 'apples', 'CA', 100L),(202002L, 2020L, 'apples', 'CA', 150L),(202001L, 2020L, 'apples', 'USA', 400L),(202002L, 2020L, 'apples', 'USA', 675L), ],
dtype=[('yyyymm', '<i8'), ('year', '<i8'), ('prod', 'O'), ('country', 'O'), ('rev', '<i8')]))
df2=df1[['yyyymm','prod','country','rev']].sort_values(['yyyymm','prod','country'])
df2['yyyymm'] = df2['yyyymm'].astype(str)
twenty_eight_days=['02']
thirty_days=['09','04','06','11']
thirty_one_days=['01','03','05','07','08','10','12']
df2['mth_nbr']=df2['yyyymm'].str[-2:]
df2['year_nbr']=df2['yyyymm'].str[:4]
df2.loc[df2['mth_nbr'].isin(twenty_eight_days), 'last_day']= '28'
df2.loc[df2['mth_nbr'].isin(thirty_days), 'last_day'] = '30'
df2.loc[df2['mth_nbr'].isin(thirty_one_days), 'last_day'] = '31'
df2['date']=pd.to_datetime(df2['year_nbr'] df2['mth_nbr'] df2['last_day'])
df2.set_index(df2['date'],inplace=True)
df2.drop(['yyyymm','mth_nbr','year_nbr','last_day','date'], axis=1, inplace=True)
df2
I break out df2 by country: df2_CA and df2_USA. I want to attach a blank dataframe called df_forecast to each of df2_CA & df2_USA so I can forecast:
# 1. : Create 2 new dfs by country: df2_CA and df2_USA:
#######################################################
for x in df2['country'].unique():
locals()['df2_' x ] = df2[(df2['country'] == x ) ]
#2. Create a forecasting dataframe:
###################################
index = pd.date_range('2020-03-30', periods=3, freq='M')
columns = ['prod','country','rev']
df_forecast = pd.DataFrame(index=index, columns=columns)
#3. Append df_forecast to each of df2_CA, df2_USA:
#################################################
df_list=[df2_CA, df2_USA]
for x in df_list:
x=pd.concat([x, df_forecast])
x['prod'].fillna(method='ffill',inplace=True)
x['country'].fillna(method='ffill',inplace=True)
x.loc['2020-03':'2020-05', 'rev'] = 200
However if I look at df2_CA, df_forecast is not appending:

When I code df2_CA (and df2_USA) separately I get the desired result:
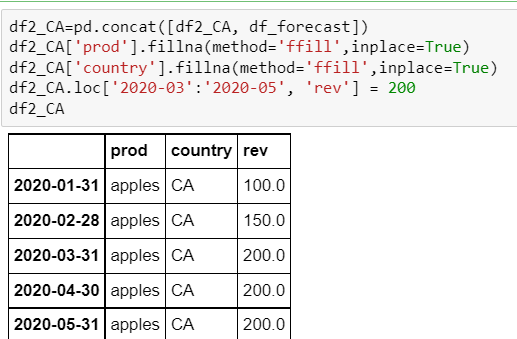
What is wrong with the for-loop in step 3 above?
CodePudding user response:
Have you made sure all dataframes have the same columns?
CodePudding user response:
Because your dataframe is blank (ie just header no rows) the concatenation has nothing to add to the existing dataframe.
You could add a first row with NaN values for instance and then edit these values later on.