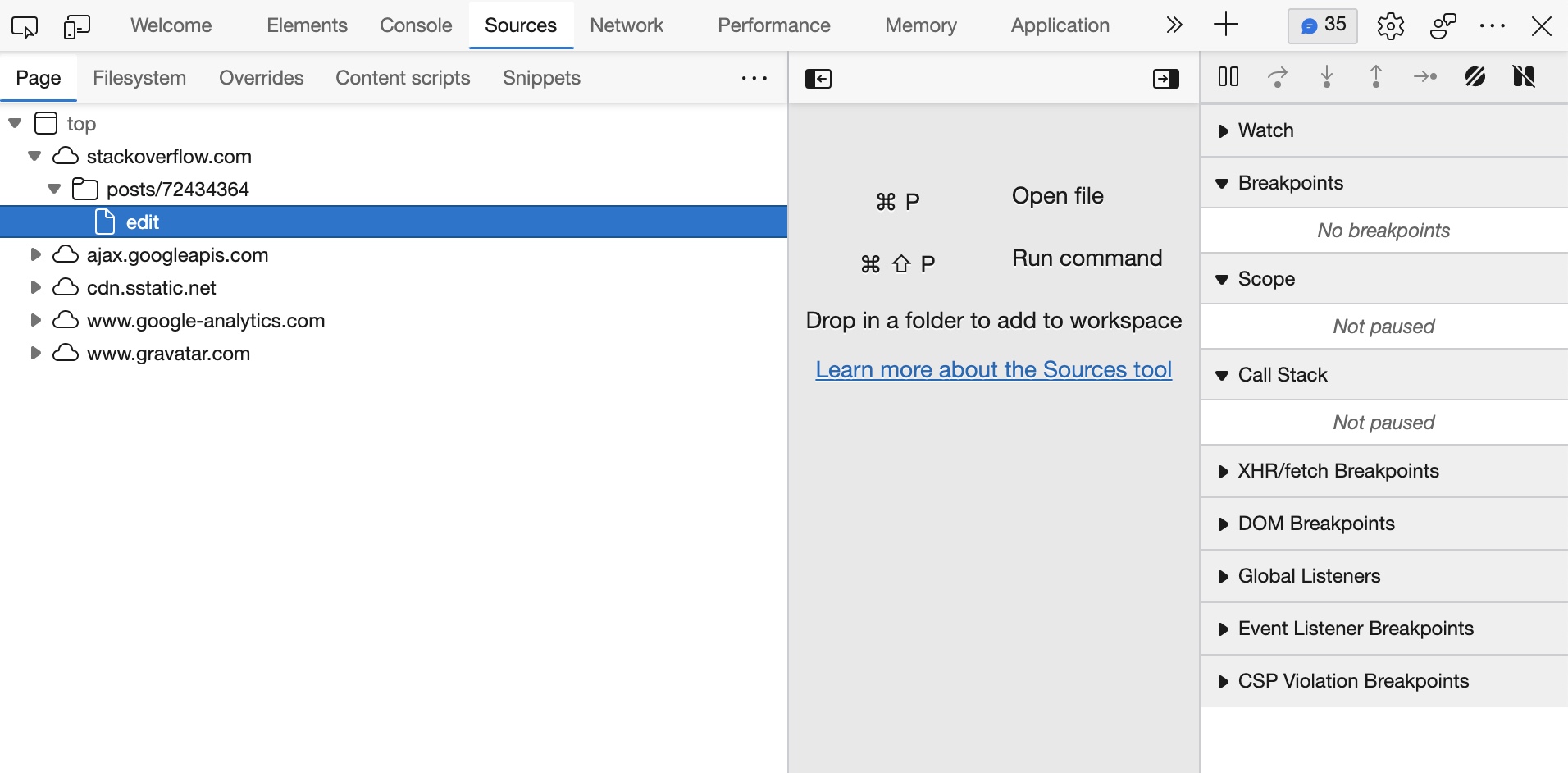
Given a website (for example stackoverflow.com) I want to download all the files under:
(Right Click) -> Inspect -> Sources -> Page
Please Try it yourself and see the files you get.
How can I do that in python? I know how to retrive page source but not the source files.
I tried searching this multiple times with no success and there is a confusion between sources (files) and page source.
Please Note, I'm looking for a an approach or example rather than ready-to-use code.
For example, I want to gather all of these files under top:
CodePudding user response:
To download website source files (mirroring websites / copy source files from websites) you may try PyWebCopy library.
To save any single page -
from pywebcopy import save_webpage
save_webpage(
url="https://httpbin.org/",
project_folder="E://savedpages//",
project_name="my_site",
bypass_robots=True,
debug=True,
open_in_browser=True,
delay=None,
threaded=False,
)
To save full website -
from pywebcopy import save_website
save_website(
url="https://httpbin.org/",
project_folder="E://savedpages//",
project_name="my_site",
bypass_robots=True,
debug=True,
open_in_browser=True,
delay=None,
threaded=False,
)
You can also check tools like httrack which comes with a GUI to download website files (mirror).
On the other hand to download web-page source code (HTML pages) -
import requests
url = 'https://stackoverflow.com/questions/72462419/how-to-download-website-source-files-in-python'
html_output_name = 'test2.html'
req = requests.get(url, 'html.parser', headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36'})
with open(html_output_name, 'w') as f:
f.write(req.text)
f.close()