I have been trying to find a method that works for what I want, but haven't had much luck. I have a large dataframe that contains information about different type of documents' statuses.
I started with something of this format:
import pandas as pd
import numpy as np
import random
list = ['Up to Date', 'Expiring Soon', 'Expired']
y = pd.DataFrame(np.random.choice(list, size=(60,6)))
y
I created several data tables grouping the information by:
a = z.groupby('Primary staff')['A Status'].value_counts()
b = z.groupby('Primary staff')['B Status'].value_counts() etc..
I then concatenated all of the created tables together which resulted in an acceptable table which looks something like:
Primary staff | A | B | C | D | E |
Bob Expired | 3 | 2 | 0 | 0 | 1 |
Expiring Soon | 10| 9 | 6 | 7 | 2 |
Up to Date | 45| 39| 61| 64| 69|
Sally Expired | 1 | 7 | 4 | 0 | 3 |
Expiring Soon | 9 | 13| 6 | 2 | 1 |
Up to Date | 35| 61| 28| 33| 70| etc.....
I would like to separate these by Primary staff, but in this table the Primary staff is no longer a column it is part of a multi-index. Ideally this would end up as a grouped bar chart or something of the sort for each primary staff keeping the document names on the x-axis and the counts on the y-axis. Any suggestions? Either a table where staff have their own sheet or a chart like the following (pardon my poor Microsoft Paint skills):
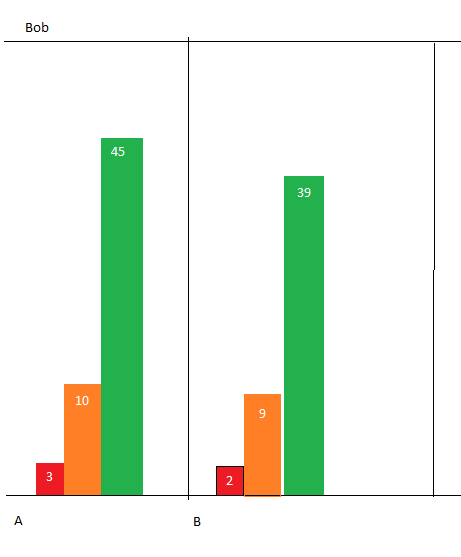
This would need to be made for each primary staff and include things like a legend, y axis, etc.
CodePudding user response:
I took your "acceptable table" and did a pandas melt.
import pandas as pd
import hvplot.pandas # noqa
pd.options.plotting.backend = 'holoviews'
df = pd.DataFrame({'Primary staff': {0: 'Bob',
1: 'Bob',
2: 'Bob',
3: 'Sally',
4: 'Sally',
5: 'Sally'},
'Status': {0: ' Expired ',
1: ' Expiring Soon',
2: ' Up to Date',
3: ' Expired ',
4: ' Expiring Soon',
5: ' Up to Date'},
'A': {0: 3, 1: 10, 2: 45, 3: 1, 4: 9, 5: 35},
'B': {0: 2, 1: 9, 2: 39, 3: 7, 4: 13, 5: 61},
'C': {0: 0, 1: 6, 2: 61, 3: 4, 4: 6, 5: 28},
'D': {0: 0, 1: 7, 2: 64, 3: 0, 4: 2, 5: 33},
'E': {0: 1, 1: 2, 2: 69, 3: 3, 4: 1, 5: 70}})
Then, using pd.melt:
new_df = pd.melt(
df, id_vars=["Primary staff", "Status"], value_vars=["A", "B", "C", "D", "E"])
Finally, use hvplot
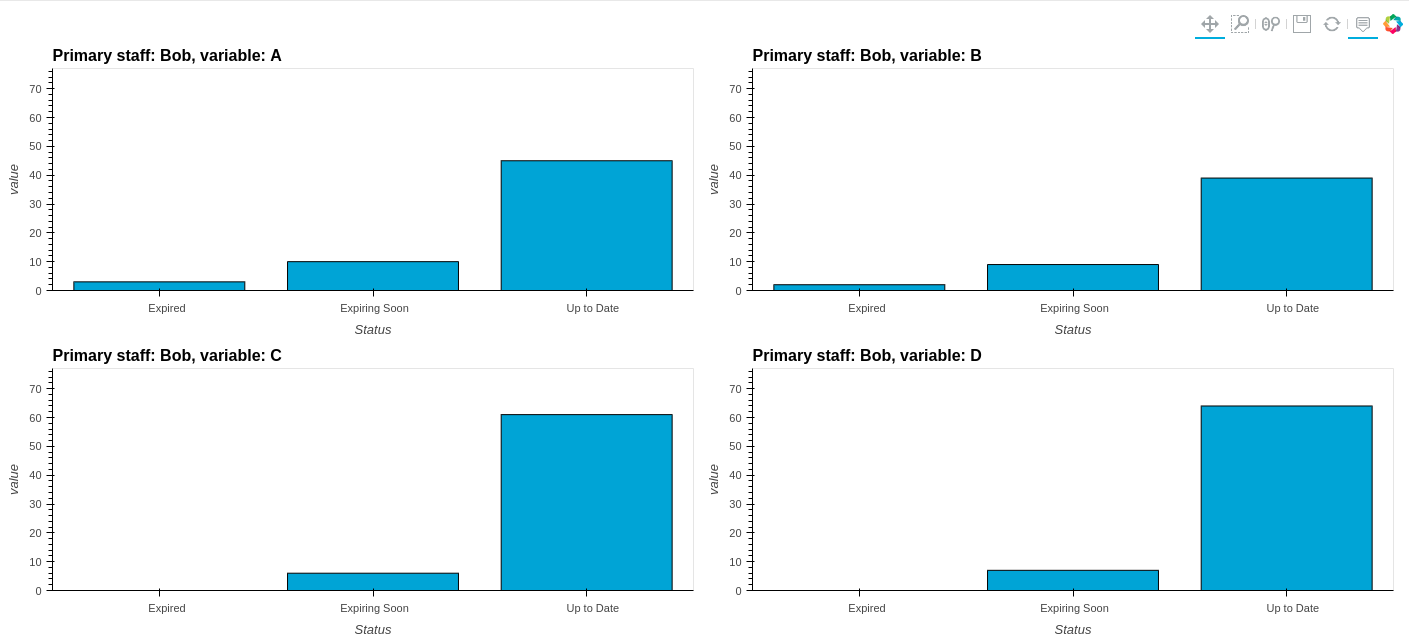
new_df.hvplot.bar(
x="Status", stacked=False, by=["Primary staff","variable"], subplots=True).cols(2)
That returns a bar chart per Primary staff and Status value with the advantage of having interactivity with the plot as well.