I am trying to read everything in excel document, that looks like this:
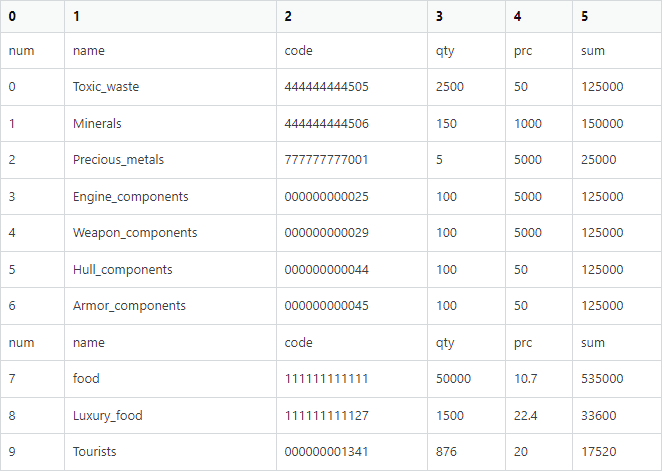
When we read the excel file
xls = pd.ExcelFile('media/No2.xls')
We are getting a problem in column 2. Instead of getting us:
code
444444444505
444444444506
444444444506
777777777001
000000000025
000000000029
000000000044
000000000045
code
111111111111
111111111127
000000001341
it gives us next:
code
444444444505
444444444506
444444444506
777777777001
25
29
44
45
code
111111111111
111111111127
1341
We need that 000000001341 to stay as 000000001341, not 1341( and also other numbers with 0s infront of em). In order to fix this issue we tried, well, everything we could find!
dtype='str'\ str \ 'string' \ object \ 'object' \ whatever
converters={"2": object\string}, converters = object\string.
In end? No changes. It still reads 000000001341 as integer and outputs it as 1341.
CodePudding user response:
Try either:
xls = pd.read_excel('media/No2.xls', converters={'code':str})
or:
xls = pd.read_excel('media/No2.xls', converters={2:str})
By default 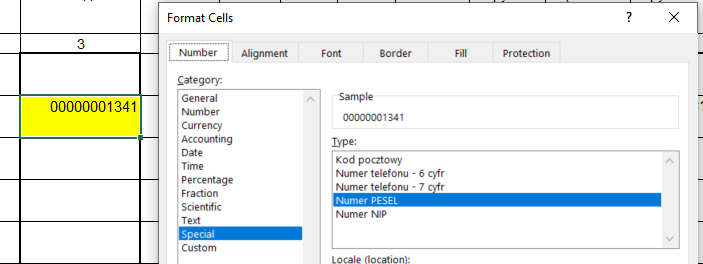
But if we apply format "General", we see that it's just a number:
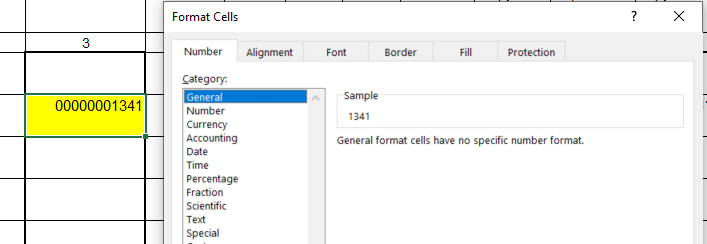
This is the reason why something like xls = pd.read_excel('media/No2.xls', converters={2:str}) has no effect, even if it is applied to the correct column index.
I've turned to xlrd for a different solution. With xlrd you can trace the number format of the cells in the sheets by adding formatting_info=True, when loading the workbook. Basically, the code below iterates over all rows and colums in the first sheet (assuming that this is the correct one) and retrieves the number format of each cell.
E.g. for the cell shown in the image above ("1341", formatted as "00000001341"), the returned value will be "00000000000". For all potential formats of this type ("0","00", etc.), we check if xls.iloc[row,col] contains an integer. If so, we change the integer to a string and add the required leading zeros by overwriting xls.iloc[row,col] with str(xls.iloc[row,col]).zfill(len(format_str)), as required. I've added a print statement for the cells that will be changed, so that you can track in the console, whether all changes make sense.
Code is as follows. Let me know if you still experience any difficulties.
import pandas as pd
# import xls, first sheet with header == None
xls = pd.read_excel('media/No2.xls', header=None)
import xlrd
# add formatting_info=True to allow for retrieving number format
book = xlrd.open_workbook('media/No2.xls', formatting_info=True)
sh = book.sheet_by_index(0)
# xlrd uses 0-index for rows, cols, e.g.: sh.cell(0,0) == A1
# from the mock data I collected the following unique formats.
# I'm assuming we only need to deal with the long strings of zeros
# the code below takes into account the possibility that the real data
# has more of these variants
# =============================================================================
# formats = ['0',
# '0000000', # this one
# '0" "',
# '00000000000', # this one
# '#,##0.00',
# '0.000',
# '0000000000', # this one
# '0.00',
# 'General']
# =============================================================================
# iterate over all rows (get length from xls DataFrame)
for row in range(xls.shape[0]):
# iterate over all cols (get length from xls DataFrame)
for col in range(xls.shape[1]):
# get format cell
cell = sh.cell(row,col)
xf_index = cell.xf_index
xf = book.xf_list[xf_index]
format_key = xf.format_key
format = book.format_map[format_key]
format_str = format.format_str
# if format like "0", "00", etc. and corresponding value in xls is an integer, define new string
if len(format_str) == format_str.count('0') and isinstance(xls.iloc[row, col],int):
temp = str(xls.iloc[row,col]).zfill(len(format_str))
# if new string (== temp) is same as the one already in xls, do nothing
# else: overwrite value
if str(xls.iloc[row,col]) != temp:
print(f'r{row} format: {format_str}; \timport: {xls.iloc[row,col]};'
f'\tchanged to: {str(xls.iloc[row,col]).zfill(len(format_str))}')
xls.iloc[row,col] = str(xls.iloc[row,col]).zfill(len(format_str))