I am currently working with the following data.
import pandas as pd
import io
csv_data = '''
gender,age,Cr,eGFR
1,76,0.56,60.7
1,50,0.76, 70.6
2,64,0.62,55.9
1,62,0.45,Nan
1,68,0.88,80.2
2,69,0.65,Nan
1,70,0.64,62.8
2,65,0.39,60.2
'''
df = pd.read_csv(io.StringIO(csv_data))
gender = 1 is male and 2 is female. This time, there are two missing values.
If it is a male:
eGFR = 194 × Cr - 1.094 × age - 0.287
If female:
eGFR = 194 × Cr - 1.094 × age - 0.287 × 0.739
I want to fill in the missing values as indicated above.
CodePudding user response:
Use 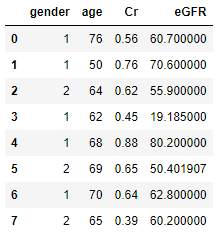
CodePudding user response:
One option is with case_when from pyjanitor, which emulates a case_when in SQL, or ifelse/multiple ifelse in python.
Do note that this is just an option; since the task is filling nulls, the idiomatic route would be a fillna and should be faster.
# pip install pyjanitor
import pandas as pd
import janitor
df = df.transform(pd.to_numeric, errors = 'coerce')
df.case_when(
# condition, result
df.eGFR.isna() & df.gender.eq(1), 194 * df.Cr - 1.094 * df.age - 0.287,
df.eGFR.isna() & df.gender.eq(2), 194 * df.Cr - 1.094 * df.age - 0.287 * 0.739,
df.eGFR, # default
column_name = 'eGFR')
gender age Cr eGFR
0 1 76 0.56 60.700000
1 1 50 0.76 70.600000
2 2 64 0.62 55.900000
3 1 62 0.45 19.185000
4 1 68 0.88 80.200000
5 2 69 0.65 50.401907
6 1 70 0.64 62.800000
7 2 65 0.39 60.200000
You can use strings for the conditions section, as long as it can be evaluated by pd.eval. Note that pd.eval might be slower than your regular bracket access option:
df.case_when(
# condition, result
'eGFR.isna() and gender==1', 194 * df.Cr - 1.094 * df.age - 0.287,
'eGFR.isna() and gender==2', 194 * df.Cr - 1.094 * df.age - 0.287 * 0.739,
df.eGFR, # default
column_name = 'eGFR')
gender age Cr eGFR
0 1 76 0.56 60.700000
1 1 50 0.76 70.600000
2 2 64 0.62 55.900000
3 1 62 0.45 19.185000
4 1 68 0.88 80.200000
5 2 69 0.65 50.401907
6 1 70 0.64 62.800000
7 2 65 0.39 60.200000