I have a dataset and stacked bar chart similar to what’s shown below. The chart is for prevalence of a specific disease (CVD=0 for no, 1 for yes) over time, by treatment type (trt=1 or 2).
I am wondering if someone could please help me with:
- Adding N for sample size under each visit number. For example, under visit=0, N=7, under visit=1, N=7, and so on.
- Annotate the graph with point estimate for prevalence of CVD and error bars for the confidence intervals? I would like the prevalence estimates to have 95% confidence intervals to better appreciate whether there was difference between treatment 1 and 2.
- get a separate table with the actual numbers for the confidence intervals.
- what is the best way to check/show if
a) change over time was statistically significant b) are there statistically significant differences between trt 1 and 2?
Any help/guidance would be appreciated.
Thanks!
Here’s a mock dataset similar to what I am working on and some code I’ve used to generate the stacked plot.
ID = c(001, 001, 001, 001, 001, 002, 002, 002, 003, 003, 004, 004, 004, 004, 005, 005, 006, 007, 007, 007, 008, 008, 008, 008, 008, 009, 009, 009, 009, 009)
Visit = c(00, 01, 02, 03, 04, 00, 01, 02, 01, 02, 00, 01, 02, 03, 00, 02, 00, 01, 02, 04, 00, 01, 02, 03, 04, 00, 01, 02, 03, 04)
CVD = c(0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0)
TRT= c(1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2)
BIO=c(12.00, 11.9, 15.24, 13.10, 30.01, 45.90, 20.09, 23.45, 14.78, 18.05,
24.23, 12.34, 80.01, 13.98, 12.50, 36.95, 29.00, 39.87, 19.03, 11.48,
14.14, 28.06, 12.22, 72.08, 15.00, 11.33, 58.00, 17.71, 52.08, 15.25)
df<-data.frame(ID,Visit, CVD, TRT, BIO)
percentData <- df %>% group_by(Visit, TRT) %>% count(CVD) %>%
mutate(ratio=scales::percent(n/sum(n))) %>%
ungroup()
ggplot(df,aes(x=Visit,fill=factor(CVD)))
geom_bar(position="fill") facet_wrap(~TRT)
geom_text(data=percentData, aes(y=n,label=ratio),
position=position_fill(vjust=0.5))
ylab('Percentage')
CodePudding user response:
This is quite a lot to ask in a single question. The way I would tackle this is to first of all generate a data frame with all the numbers you will need for plotting and tabling results:
library(tidyverse)
df2 <- df %>%
group_by(Visit, TRT) %>%
summarize(no_CVD = table(factor(CVD, 0:1))[1],
CVD = table(factor(CVD, 0:1))[2],
n = no_CVD CVD,
prop = CVD / n,
lower = suppressWarnings(prop.test(CVD, n)$conf.int[1]),
upper = suppressWarnings(prop.test(CVD, n)$conf.int[2])) %>%
mutate(Percent = scales::percent(prop, 0.1),
CI = paste0("(", scales::percent(lower, 0.1), " - ",
scales::percent(upper, 0.1), ")"),
TRT = paste("Treatment", TRT))
You can see this gives us the point estimates and confidence intervals as both raw proportions and as text labels, which should be adequate to fulfill question 3:
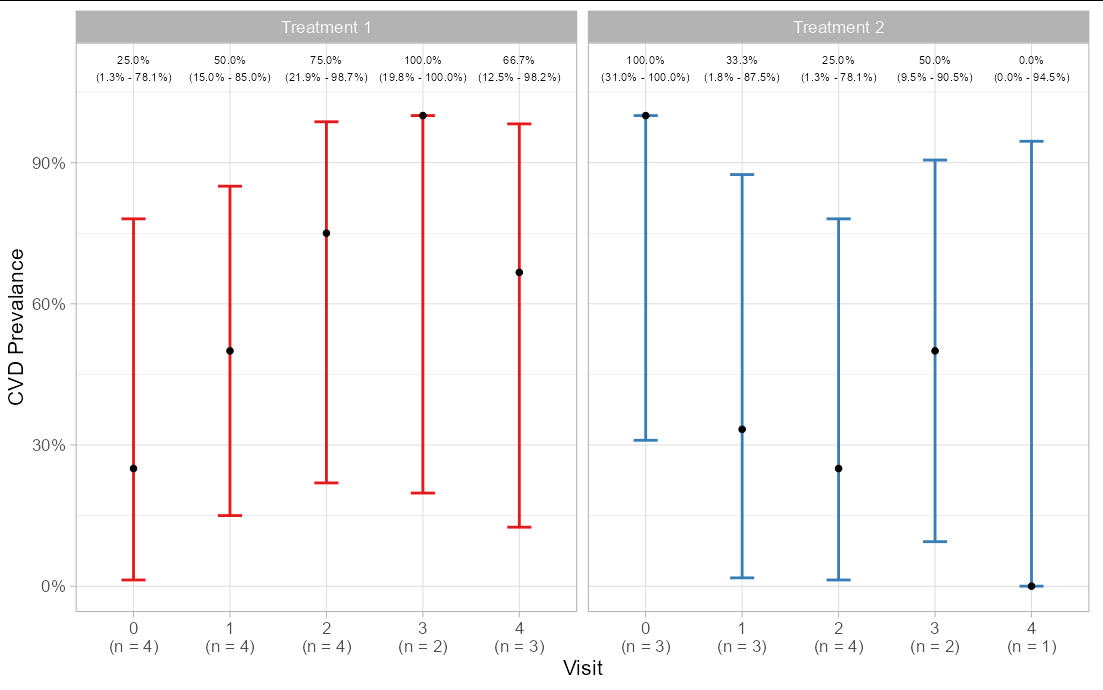
df2
#> # A tibble: 10 x 10
#> # Groups: Visit [5]
#> Visit TRT no_CVD CVD n prop lower upper Percent CI
#> <dbl> <chr> <int> <int> <int> <dbl> <dbl> <dbl> <chr> <chr>
#> 1 0 Treatment 1 3 1 4 0.25 0.0132 0.781 25.0% (1.3% - 78.1~
#> 2 0 Treatment 2 0 3 3 1 0.310 1 100.0% (31.0% - 100~
#> 3 1 Treatment 1 2 2 4 0.5 0.150 0.850 50.0% (15.0% - 85.~
#> 4 1 Treatment 2 2 1 3 0.333 0.0177 0.875 33.3% (1.8% - 87.5~
#> 5 2 Treatment 1 1 3 4 0.75 0.219 0.987 75.0% (21.9% - 98.~
#> 6 2 Treatment 2 3 1 4 0.25 0.0132 0.781 25.0% (1.3% - 78.1~
#> 7 3 Treatment 1 0 2 2 1 0.198 1 100.0% (19.8% - 100~
#> 8 3 Treatment 2 1 1 2 0.5 0.0945 0.905 50.0% (9.5% - 90.5~
#> 9 4 Treatment 1 1 2 3 0.667 0.125 0.982 66.7% (12.5% - 98.~
#> 10 4 Treatment 2 1 0 1 0 0 0.945 0.0% (0.0% - 94.5~
To put the N under each visit, we can simply paste the visit number with a string containing the counts from this table (this handles question 1).
Question 2 is a little odd. The sample prevalence of CVD was already present on your plot (that's what the blue bars showed). Adding error bars to a stacked bar graph is going to look messy, and the bars don't actually give any information that a simple point does in this scenario. I have therefore changed the plot to show points with error bars.
ggplot(df2, aes(paste0(Visit, "\n(n = ", n, ")"), prop))
geom_errorbar(aes(ymin = lower, ymax = upper, color = factor(TRT)),
size = 1, width = 0.25)
geom_point(size = 2)
geom_text(aes(label = paste(Percent, CI, sep = "\n"), y = 1.1), size = 3)
facet_grid(.~TRT, scales = "free_x")
scale_y_continuous(labels = scales::percent, name = "CVD Prevalance")
xlab("Visit")
theme_light(base_size = 16)
theme(legend.position = "none")
scale_color_brewer(palette = "Set1")
Your last two points are statistical rather than programming questions, so are off-topic here. It is likely that you need a binomial generalized linear mixed model to handle the repeated measures, but you should post that question on CrossValidated, our sister site for stats questions if you do not have access to a statistician.
Created on 2022-06-21 by the reprex package (v2.0.1)