I'm trying to learn Pandas and I'm having difficulties to achieve a simple goal.
I have a dataset where I want to transpose the rows of a column in multiple column (check img). The column "Maximum take-off weight and type of power plant" has 12 different values and the goal is to achive this values become columns filled with "VALUE". It's also important to keep the other columns, later in the process I will eliminate some of them but I was wondering if it's possible to achieve the goal anyway, I know some of the values in this rows will be lost, like 'COORDINATE'.
I have read the documentation about 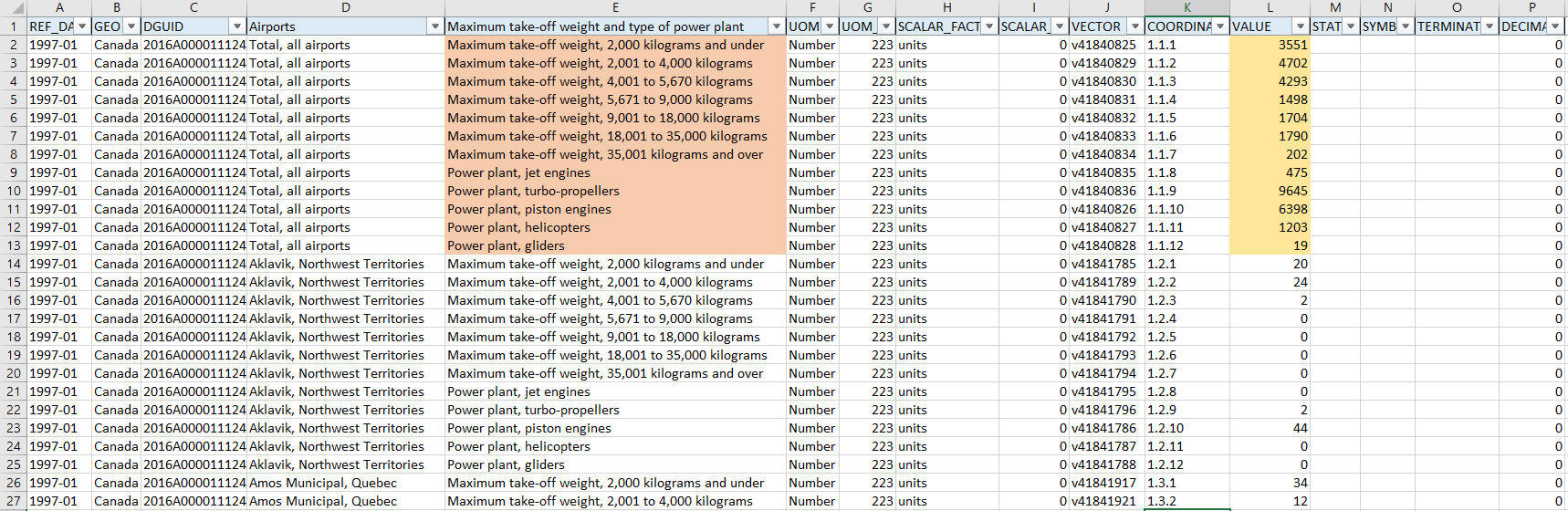
The output should be something like this:

Input sample:
"REF_DATE","GEO","DGUID","Airports","Maximum take-off weight and type of power plant","UOM","UOM_ID","SCALAR_FACTOR","SCALAR_ID","VECTOR","COORDINATE","VALUE","STATUS","SYMBOL","TERMINATED","DECIMALS"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 2,000 kilograms and under","Number","223","units ","0","v41840825","1.1.1","3551","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 2,001 to 4,000 kilograms","Number","223","units ","0","v41840829","1.1.2","4702","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 4,001 to 5,670 kilograms","Number","223","units ","0","v41840830","1.1.3","4293","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 5,671 to 9,000 kilograms","Number","223","units ","0","v41840831","1.1.4","1498","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 9,001 to 18,000 kilograms","Number","223","units ","0","v41840832","1.1.5","1704","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 18,001 to 35,000 kilograms","Number","223","units ","0","v41840833","1.1.6","1790","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 35,001 kilograms and over","Number","223","units ","0","v41840834","1.1.7","202","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, jet engines","Number","223","units ","0","v41840835","1.1.8","475","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, turbo-propellers","Number","223","units ","0","v41840836","1.1.9","9645","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, piston engines","Number","223","units ","0","v41840826","1.1.10","6398","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, helicopters","Number","223","units ","0","v41840827","1.1.11","1203","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, gliders","Number","223","units ","0","v41840828","1.1.12","19","","","","0"
CodePudding user response:
Based on the example in your question, it looks like you only need the Value entry in the first row matching each unique Maximum take-off weight and type of power plant entry.
Here is a way to do what you've asked (for simplicity, I have shortened the column name to Max weight and type, reduced the number of columns and used arbitrary values):
x = df.drop_duplicates('Max weight and type')
y = x[['Max weight and type', 'Value']].set_index('Max weight and type').T.reset_index(drop=True)
y.columns.name=None
cols = list(x.columns)
iWt, iVal = cols.index('Max weight and type'), cols.index('Value')
cols = cols[:iWt] list(y.columns) cols[iWt 1:iVal] cols[iVal 1:]
res = x.loc[0,:].drop(columns=['Max weight and type', 'Value']).to_frame().T.reindex(
columns=cols).assign(**{k:v[0] for k, v in y.to_dict().items()})
Sample input:
Airports Max weight and type Value COORDINATES
0 Total, all airports x1 50 1.1.1
1 Total, all airports x2 100 1.1.2
2 Total, all airports x3 150 1.1.3
3 Total, all airports x4 200 1.1.4
4 Total, all airports x1 55 1.1.5
5 Total, all airports x2 105 1.1.6
6 Total, all airports x3 155 1.1.7
Output:
Airports x1 x2 x3 x4 COORDINATES
0 Total, all airports 50 100 150 200 1.1.1
Explanation:
- Use
drop_duplicates()to eliminate all but the first row for each unique value in theMax weight and typecolumn - Create a new DataFrame whose column labels are the unique values from
Max weight and typeand whose only row contains theValueentry in the first row of the original dataframe matching each uniqueMax weight and typeentry - Make a column label list which replaces
Max weight and typewith its unique values and eliminatesValuefrom the original dataframe's column labels - Drop the columns to be replaced (
Max weight and type,Value), usereindex()to add theMax weight and typevalues as column labels (with NaN values initially), and useassign()to overwrite the NaN values in these new columns with the correspondingValueentries from the original dataframe.
CodePudding user response:
In case you want to keep the original df and just add some columns with names and values from two different existing columns you can try this with remark that the original values populate just the first row of new columns. Regards...
import pandas as pd
# sample dictionary
data = {'A': [11,47,33],
'B': ['max_x','max_y','max_z'],
'C': [77,56,99]
}
# sample df
df = pd.DataFrame(data, columns = ['A', 'B', 'C'])
# Create two lists of columns containing names and values for new columns
b_list = list(df['B'])
c_list = list(df['C'])
# To keep the whole df as it is and add some new columns get the length of the series in the column (number of rows)
list_length = len(b_list)
# for new column create list populated with zeros so you would have a list of the size of the df series
i = 0
new_col_list = []
for i in range(list_length):
new_col_list.append(0)
# insert columns
for i in range(list_length):
# put the value from your original df in the first element of the new_col_list, all others will be zeros
new_col_list[0] = c_list[i]
# create and execute the command to insert a new column at position where you want (the end in this case)
cmd = 'df.insert(' str(len(b_list) i) ', "' str(b_list[i]) '", ' str(new_col_list) ', True)'
exec(cmd)
i = 1
print(df)
#
# Original df
#
# A B C
# 0 11 max_x 77
# 1 47 max_y 56
# 2 33 max_z 99
#
#
# Insert commands generated in this script are:
#
# df.insert(3, "max_x", [77, 0, 0], True)
# df.insert(4, "max_y", [56, 0, 0], True)
# df.insert(5, "max_z", [99, 0, 0], True)
#
# ---------------------------------------------
# R e s u l t :
#
# A B C max_x max_y max_z
# 0 11 max_x 77 77 56 99
# 1 47 max_y 56 0 0 0
# 2 33 max_z 99 0 0 0
CodePudding user response:
you can try:
import pandas as pd
from io import StringIO
#pd.set_option('display.max_colwidth', 10)
#pd.set_option('display.max_columns', None)
df = """
"REF_DATE","GEO","DGUID","Airports","Maximum take-off weight and type of power plant","UOM","UOM_ID","SCALAR_FACTOR","SCALAR_ID","VECTOR","COORDINATE","VALUE","STATUS","SYMBOL","TERMINATED","DECIMALS"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 2,000 kilograms and under","Number","223","units ","0","v41840825","1.1.1","3551","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 2,001 to 4,000 kilograms","Number","223","units ","0","v41840829","1.1.2","4702","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 4,001 to 5,670 kilograms","Number","223","units ","0","v41840830","1.1.3","4293","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 5,671 to 9,000 kilograms","Number","223","units ","0","v41840831","1.1.4","1498","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 9,001 to 18,000 kilograms","Number","223","units ","0","v41840832","1.1.5","1704","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 18,001 to 35,000 kilograms","Number","223","units ","0","v41840833","1.1.6","1790","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Maximum take-off weight, 35,001 kilograms and over","Number","223","units ","0","v41840834","1.1.7","202","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, jet engines","Number","223","units ","0","v41840835","1.1.8","475","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, turbo-propellers","Number","223","units ","0","v41840836","1.1.9","9645","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, piston engines","Number","223","units ","0","v41840826","1.1.10","6398","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, helicopters","Number","223","units ","0","v41840827","1.1.11","1203","","","","0"
"1997-01","Canada","2016A000011124","Total, all airports","Power plant, gliders","Number","223","units ","0","v41840828","1.1.12","19","","","","0"
"1997-01","Canada","2016A000011125","Test2","Power plant, piston engines","Number","223","units ","0","v41840826","1.1.10","10000","","","","0"
"1997-01","Canada","2016A000011125","Test2","Power plant, helicopters","Number","223","units ","0","v41840827","1.1.11","10001","","","","0"
"1997-01","Canada","2016A000011125","Test2","Power plant, gliders","Number","223","units ","0","v41840828","1.1.12","10002","","","","0"
"""
df = pd.read_csv(StringIO(df.strip()), sep=',')
#create a pivot to have one line per DGUID
df1=pd.pivot_table(df, values='VALUE', index='DGUID', columns='Maximum take-off weight and type of power plant').fillna(0).reset_index()
#Merge pivot with intial df
df=df.merge(df1,on='DGUID')
print("----------------------")
print('with All lines:')
print(df)
#if only first line of each DGUID is intereting:
df.drop_duplicates('DGUID',inplace=True)
print("----------------------")
print('Duplicates on DGUID removed:')
print(df)
Result:
----------------------
with All lines:
REF_DATE GEO DGUID Airports ... Power plant, helicopters Power plant, jet engines Power plant, piston engines Power plant, turbo-propellers
0 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
1 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
2 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
3 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
4 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
5 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
6 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
7 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
8 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
9 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
10 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
11 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
12 1997-01 Canada 2016A000011125 Test2 ... 10001.0 0.0 10000.0 0.0
13 1997-01 Canada 2016A000011125 Test2 ... 10001.0 0.0 10000.0 0.0
14 1997-01 Canada 2016A000011125 Test2 ... 10001.0 0.0 10000.0 0.0
[15 rows x 28 columns]
----------------------
Duplicates on DGUID removed:
REF_DATE GEO DGUID Airports ... Power plant, helicopters Power plant, jet engines Power plant, piston engines Power plant, turbo-propellers
0 1997-01 Canada 2016A000011124 Total, all airports ... 1203.0 475.0 6398.0 9645.0
12 1997-01 Canada 2016A000011125 Test2 ... 10001.0 0.0 10000.0 0.0
[2 rows x 28 columns]