i have a pdf file stored in a server url, and i want to get each line of the file, i want later export it to an excel file so i need to get every line, one by one, i will put the code here. OBS: the url of the pdf stop working after 3 hours, i will always update it here in the comments. thanks.
using System;
using System.Net.Http;
using System.Threading.Tasks;
public class Program
{
public static async Task Main()
{
var pdfUrl = "https://eproc.trf4.jus.br/eproc2trf4/controlador.php?acao=acessar_documento_implementacao&doc=41625504719486351366932807019&evento=20084&key=4baa2515293382eb41b2a95e121550490b5b154f1c4c06e8b0469eff082311e6&hash=3112f8451af24a1a5c3e69afab09f079&termosPesquisados=";
var client = new HttpClient();
var response = await client.GetAsync(pdfUrl);
using (var stream = await response.Content.ReadAsStreamAsync())
{
Console.WriteLine("print each line of my pdf file");
}
}
}
CodePudding user response:
Well, extracting text from PDF is not an ordinary task. If you need really generic solution works with any pdf, then state of art solution here is to use AI based API provided for example by some cloud platforms like Google, AWS or Azure:
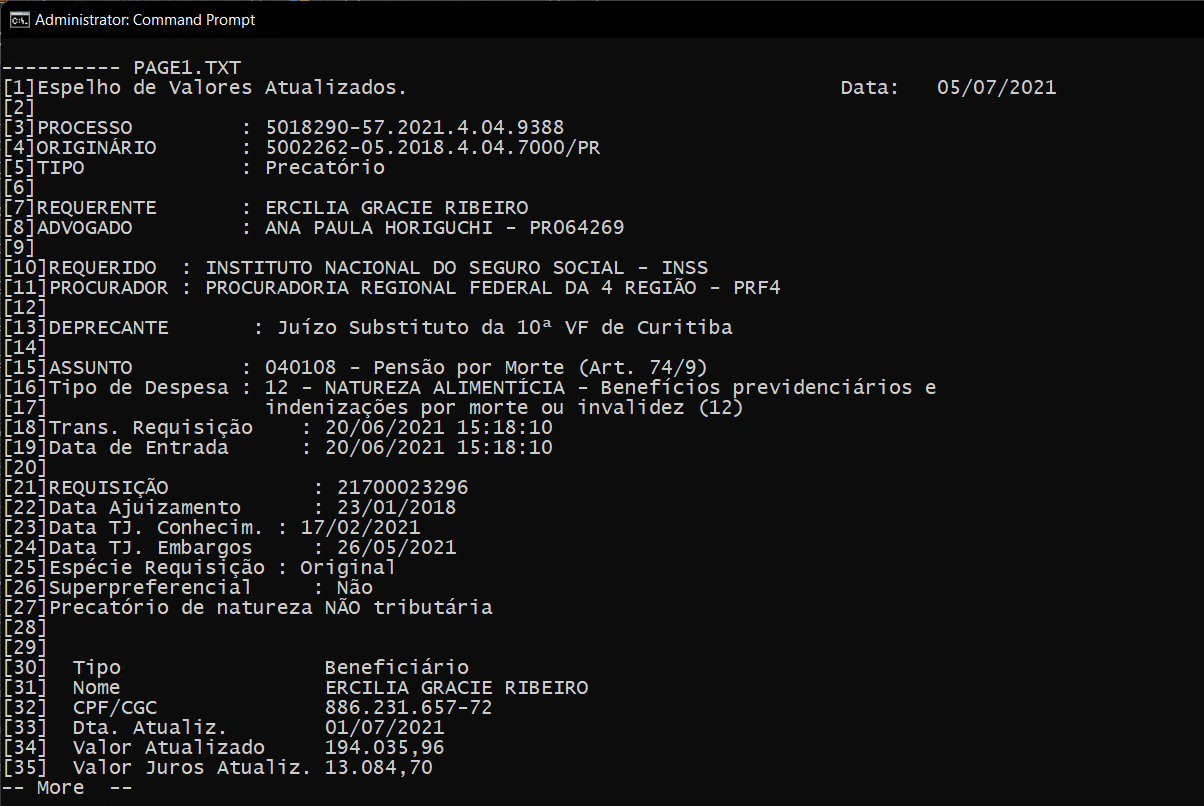
Page 1.txt
Espelho de Valores Atualizados. Data: 05/07/2021
PROCESSO : 5018290-57.2021.4.04.9388
ORIGINÁRIO : 5002262-05.2018.4.04.7000/PR
TIPO : Precatório
REQUERENTE : ERCILIA GRACIE RIBEIRO
ADVOGADO : ANA PAULA HORIGUCHI - PR064269
REQUERIDO : INSTITUTO NACIONAL DO SEGURO SOCIAL - INSS
PROCURADOR : PROCURADORIA REGIONAL FEDERAL DA 4 REGIÃO - PRF4
DEPRECANTE : Juízo Substituto da 10ª VF de Curitiba
etc.....