I've read in a csv in Pandas that has a variance in row values and some blank lines in between the rows.
Example:
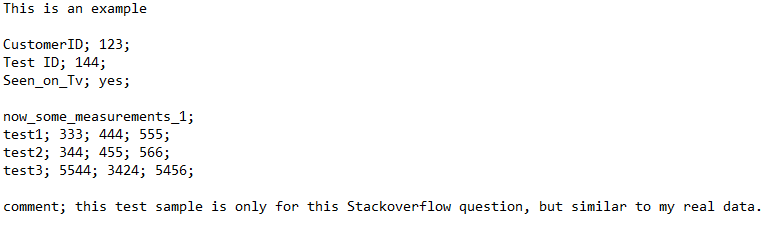
This is an example
CustomerID; 123;
Test ID; 144;
Seen_on_Tv; yes;
now_some_measurements_1;
test1; 333; 444; 555;
test2; 344; 455; 566;
test3; 5544; 3424; 5456;
comment; this test sample is only for this Stackoverflow question, but
similar to my real data.
When reading in this file, I use this code:
pat = pd.read_csv(FileName, skip_blank_lines = False, header=None, sep=";", names=['a', 'b', 'c', 'd', 'e'])
pat.head(10)
output:
a b c d e
0 This is an example NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN
2 CustomerID 123 NaN NaN NaN
3 Test ID 144 NaN NaN NaN
4 Seen_on_Tv yes NaN NaN NaN
5 NaN NaN NaN NaN NaN
6 now_some_measurements_1 NaN NaN NaN NaN
7 test1 333 444.0 555.0
8 test2 344 455.0 566.0 NaN
9 test3 5544 3424.0 5456.0 NaN
This works, especially since I have to change the CustomerID (via this code example) etc:
newID = 'HASHED'
pat.loc[pat['a'] == 'CustomerID', 'b']=newID
However, when I save this changed dataframe to csv, I get a lot of 'trailing' seperators (";") as most of the columns are empty and especially with the blank lines.
pat.to_csv('out.csv', sep=";", index = False, header=False)
output (out.csv):
This is an example;;;;
;;;;
CustomerID; HASHED;;;
Test ID; 144;;;
Seen_on_Tv; yes;;;
;;;;
now_some_measurements_1;;;;
test1; 333;444.0;555.0;
test2; 344;455.0;566.0;
test3; 5544;3424.0;5456.0;
;;;;
comment; this test sample is only for this Stackoverflow question, but similar to my real
data.
;;;
I've searched almost everywhere for a solution, but can not find it. How to write only the column values to the csv file that are not blank (except for the blank lines to separate the sections, which need to remain blank of course)?
Thank you in advance for your kind help.
CodePudding user response:
A simple way would be to just parse your out.csv and for the non-blank lines (those consisting solely of ;'s) - write a stripped version of that line, eg:
with open('out.csv') as fin, open('out2.csv', 'w') as fout:
for line in fin:
if stripped := line.strip(';\n '):
fout.write(stripped '\n')
else:
fout.write(line)
Will give you:
This is an example
;;;;
CustomerID; HASHED
Test ID; 144
Seen_on_Tv; yes
;;;;
now_some_measurements_1
test1; 333;444.0;555.0
test2; 344;455.0;566.0
test3; 5544;3424.0;5456.0
;;;;
comment; this test sample is only for this Stackoverflow question, but similar to my real
data.
;;;
You could also pass a io.StringIO object to to_csv (to save writing to disk and then re-reading) as the output destination, then parse that in a similar fashion to produce your desired output file.