I have a df that looks like this:
d = {'type': ['A', 'A', 'A' ,'A' , 'A', 'A', 'A','A' ,'A' ,'A', 'A', 'A', 'A','B', 'B', 'B' ,'B' , 'B', 'B', 'B','B' ,'B' ,'B', 'B', 'B', 'B'],
'Date': ['Jun-21','Jul-21','Aug-21','Sep-21','Oct-21','Nov-21','Dec-21','Jan-22','Feb-22','Mar-22','Apr-22','May-22','Jun-22', 'Jun-21','Jul-21','Aug-21','Sep-21','Oct-21','Nov-21','Dec-21','Jan-22','Feb-22','Mar-22','Apr-22','May-22','Jun-22'],
'Units':[0, 0, 0, 0, 10, 0, 20, 0, 0, 7, 12, 35, 0, 0,0,0,0,7,4,0,4,9,5,8,3,11]}
df = pd.DataFrame(data=d)
Type Date Value
A Jun-21 0
A Jul-21 0
A Aug-21 0
A Sep-21 0
A Oct-21 10
A Nov-21 0
A Dec-21 20
A Jan-22 0
A Feb-22 0
A Mar-22 7
A Apr-22 12
A May-22 35
A Jun-22 0
B Jun-21 0
B Jul-21 0
B Aug-21 0
B Sep-21 0
B Oct-21 7
B Nov-21 4
B Dec-21 0
B Jan-22 4
B Feb-22 9
B Mar-22 5
B Apr-22 8
B May-22 3
B Jun-22 11
I've got a function by googling and asking another question in stack overflow that calculates a certain value that I need:
def my_function(df):
df['Expected'] = 0
for i in range(1, len(df)):
if df['Units'][i] == 0:
df['Expected'][i] = df['Expected'][i-1]
if df['Units'][i] > 0:
df['Expected'][i] = ((df['Units'][i]-2*df['Expected'][i-1])//5).clip(0) df['Expected'][i-1].cumsum()
However, how can I adapt this function so that it can work over different groups for my data. Currently my function is only accurate when I pass it one group at a time. I've tried a few different methods including "for _, group_key in groups:" but I can't seem to get the function to work for each group that my data has.
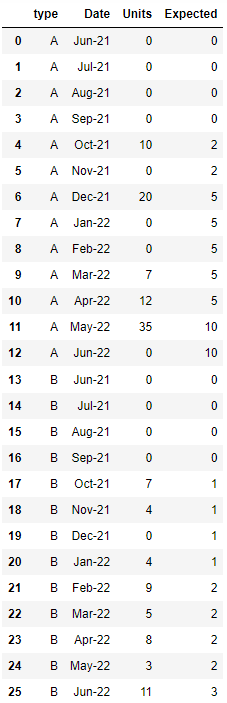
My expected output should be this:
Type Date Value Expected
A Jun-21 0 0
A Jul-21 0 0
A Aug-21 0 0
A Sep-21 0 0
A Oct-21 10 2
A Nov-21 0 2
A Dec-21 20 5
A Jan-22 0 5
A Feb-22 0 5
A Mar-22 7 5
A Apr-22 12 5
A May-22 35 10
A Jun-22 0 10
B Jun-21 0 0
B Jul-21 0 0
B Aug-21 0 0
B Sep-21 0 0
B Oct-21 7 1
B Nov-21 4 1
B Dec-21 0 1
B Jan-22 4 1
B Feb-22 9 2
B Mar-22 5 2
B Apr-22 8 2
B May-22 3 2
B Jun-22 11 3
It works fine passing each group to the function separately, but was just wondering what would be the best way to get this to work for each group in one go. Any help is greatly appreciated!
CodePudding user response:
Try grouping by type and apply my_function(). One change to make it work is to iterate over the index instead of range(len(df)), because the program needs to run in different groups.
def my_function(d):
# initialize with 0
d['Expected'] = 0
# iterate over the index
for i in d.index[1:]:
if d.loc[i, 'Units'] == 0:
d.loc[i, 'Expected'] = d.loc[i-1, 'Expected']
elif d.loc[i, 'Units'] > 0:
d.loc[i, 'Expected'] = d.loc[i-1, 'Expected'] (d.loc[i, 'Units'] - 2 * d.loc[i-1, 'Expected']).clip(0)//5
return d
# apply the function by types
df = df.groupby('type').apply(my_function)
df
I also cleaned up my_function() a little by using .loc instead of [][], removed the unnecessary cumsum() (df['Expected'][i-1].cumsum() is a single value so cumsum() is redundant) and made the floor-division (//) after addition (because there is clip(0), the function doesn't change) to get rid of one extra layer of brackets.