I have a data frame in PySpark and would like to save the file as a CSV with the current timestamp as a file name. I am executing this in Azure Synapse Notebook and would like to run the notebook every day.
I stored my data frame as "df"
Using the below code, saving file as {date}.csv
from datetime import datetime
date = datetime.now().strftime("%Y_%m_%d-%I:%M:%S_%p")
df.coalesce(1).write.option("mode","append").option("header","true").option("sep",",").csv("abfss://[email protected]/{date}.csv")
I am saving the CSV file in the data lake and it saving as "{date}.csv" as a folder and inside I can see the CSV file.
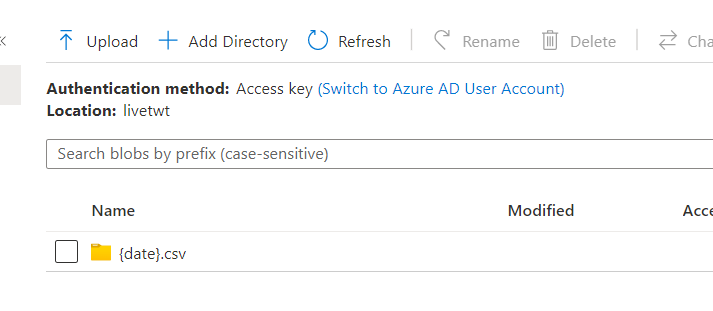
Inside folder
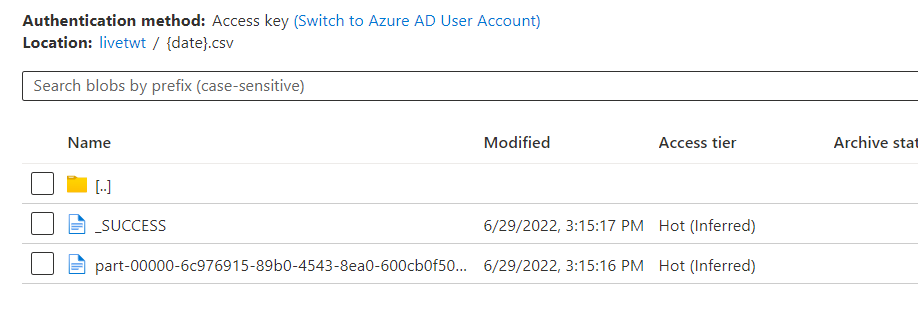
Required Output:
I need the file name to be "29-06-2022 15:30:25 PM.csv" without creating a new folder. I am running the notebook every day so each day, the file will be in the current date format.
Can anyone advise, what is the issue in the above code?
Note that I need to execute this only in PySpark, not in Python.
CodePudding user response:
You do everything right, just add an f before the string. Then it will accept the date variable:
.csv(f"abfss://[email protected]/{date}.csv")
CodePudding user response:
You can also use to separate file path string values with variables as below
from datetime import datetime
date = datetime.now().strftime("%Y_%m_%d-%I:%M:%S_%p")
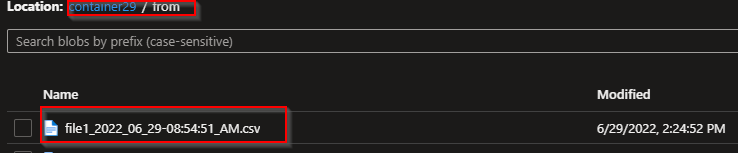
df.to_csv("abfss://<container_name>@<storage_accountname>.dfs.core.windows.net/from/file1_" date ".csv", sep=',', encoding='utf-8', index=False)

Output: