i have a pandas dataframe
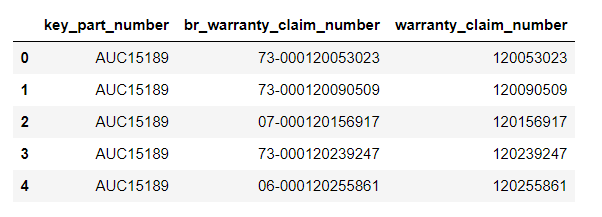
where you can find 3 columns. the third is the second one with some str slicing. To every warranty_claim_number, there is a key_part_number (first column).
this dataframe has a lot of rows.
I have a second list, which contains 70 random select warranty_claim_numbers.
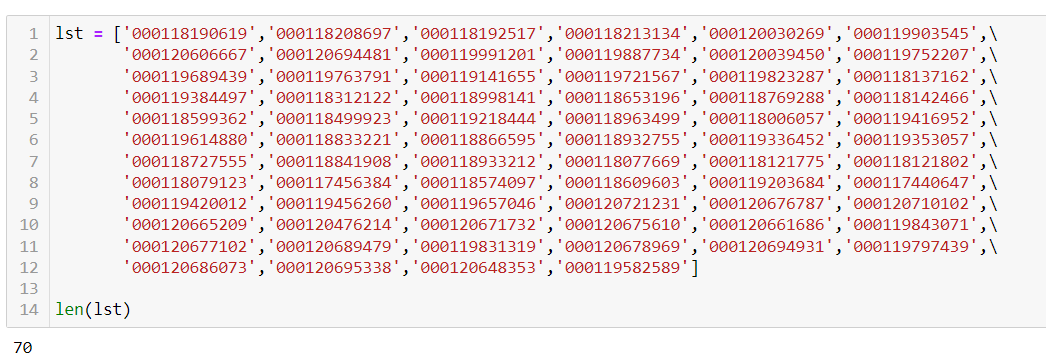
I was hoping to find the corresponding key_part_number from those 70 claims in my dataset.
Then i would like to create a dictionary with the key_part_number as key and the corresponding value as warranty_claim_number.
At last, count how often each key_part_number appears in this dataset and update the key.
This should like like this:
dicti = {4:'000120648353',10:'000119582589',....}
CodePudding user response:
first of all you need to change the datatype of warranty_claim_numbers to string or you wont get the leading 0's
You can subset your df form that list of claim numbers:
df = df[df["warranty_claim_number"].isin(claimnumberlist)]
This gives you a dataframe with only the rows with those claim numbers.
countofkeyparts = df["key_part_number"].value_counts()
this gives you a pandas series with the values and you can cast i to a dict with to_dict()
countofkeyparts = countofkeyparts.to_dict()
The keys in a dict have to be unique so if you want the count as a key you can have the value be a list of key_part_numbers
values = {}
for key, value in countofkeyparts.items():
values[value]= values.get(value,[])
values[value].append(key)
CodePudding user response:
According to your example, you can't use the number of occurrences as the key of the dictionary because the key in the dictionary is unique and you can't exclude multiple data columns with the same frequency of occurrence, so it is recommended to set the result in this format: dicti = {4:['000120648353', '09824091'],10:['000119582589'] ,....}
I'll use randomly generated data as an example
from collections import Counter
import random
lst = [random.randint(1, 10) for i in range(20)]
counter = Counter(lst)
print(counter) # First element, then number of occurrences
nums = set(counter.values()) # All occurrences
res = {item: [val for val in counter if counter[val] == item] for item in nums}
print(res)
# Counter({5: 6, 8: 4, 3: 2, 4: 2, 9: 2, 2: 2, 6: 1, 10: 1})
# {1: [6, 10], 2: [3, 4, 9, 2], 4: [8], 6: [5]}
CodePudding user response:
This does what you want:
# Select rows where warranty_claim_numbers item is in lst:
df_wanted = df.loc[df["warranty_claim_numbers"].isin(lst), "warranty_claim_numbers"]
# Count the values in that row:
count_values = df_wanted.value_counts()
# Transform to Dictionary:
print(count_values.to_dict())