I'm trying to loop through a series of tickers cleaning the associated dataframes then combining the individual ticker dataframes into one large dataframe with columns named for each ticker. The following code enables me to loop through unique tickers and name the columns of each ticker's dataframe after the specific ticker:
import pandas as pd
def clean_func(tkr,f1):
f1['Date'] = pd.to_datetime(f1['Date'])
f1.index = f1['Date']
keep = ['Col1','Col2']
f2 = f1[keep]
f2.columns = [tkr 'Col1',tkr 'Col2']
return f2
tkrs = ['tkr1','tkr2','tkr3']
for tkr in tkrs:
df1 = pd.read_csv(f'C:\\path\\{tkr}.csv')
df2 = clean_func(tkr,df1)
However, I don't know how to create a master dataframe where I add each new ticker to the master dataframe. With that in mind, I'd like to align each new ticker's data using the datetime index. So, if tkr1 has data for 6/25/22, 6/26/22, 6/27/22, and tkr2 has data for 6/26/22, and 6/27/22, the combined dataframe would show all three dates but would produce a NaN for ticker 2 on 6/25/22 since there is no data for that ticker on that date.
When not in a loop looking to append each successive ticker to a larger dataframe (as per above), the following code does what I'd like. But it doesn't work when looping and adding new ticker data for each successive loop (or I don't know how to make it work in the confines of a loop).
combined = pd.concat((df1, df2, df3,...,dfn), axis=1)
Many thanks in advance.
CodePudding user response:
You should only create the master DataFrame after the loop. Appending to the master DataFrame in each iteration via pandas.concat is slow since you are creating a new DataFrame every time.
Instead, read each ticker DataFrame, clean it, and append it to a list which store every ticker DataFrames. After the loop create the master DataFrame with all the Dataframes using pandas.concat:
import pandas as pd
def clean_func(tkr,f1):
f1['Date'] = pd.to_datetime(f1['Date'])
f1.index = f1['Date']
keep = ['Col1','Col2']
f2 = f1[keep]
f2.columns = [tkr 'Col1',tkr 'Col2']
return f2
tkrs = ['tkr1','tkr2','tkr3']
dfs_list = []
for tkr in tkrs:
df1 = pd.read_csv(f'C:\\path\\{tkr}.csv')
df2 = clean_func(tkr,df1)
dfs_list.append(df2)
master_df = pd.concat(dfs_list, axis=1)
As a suggestion here is a cleaner way of defining your clean_func using DataFrame.set_index and DataFrame.add_prefix.
def clean_func(tkr, f1):
f1['Date'] = pd.to_datetime(f1['Date'])
f2 = f1.set_index('Date')[['Col1','Col2']].add_prefix(tkr)
return f2
Or if you want, you can parse the Date column as datetime and set it as index directly in the pd.read_csv call by specifying index_col and parse_dates parameters (honestly, I'm not sure if those two parameters will play well together, and I'm too lazy to test it, but you can try ;)).
import pandas as pd
def clean_func(tkr,f1):
f2 = f1[['Col1','Col2']].add_prefix(tkr)
return f2
tkrs = ['tkr1','tkr2','tkr3']
dfs_list = []
for tkr in tkrs:
df1 = pd.read_csv(f'C:\\path\\{tkr}.csv', index_col='Date', parse_dates=['Date'])
df2 = clean_func(tkr,df1)
dfs_list.append(df2)
master_df = pd.concat(dfs_list, axis=1)
CodePudding user response:
Before the loop create an empty df with:
combined = pd.DataFrame()
Then within the loop (after loading df1 - see code above):
combined = pd.concat((combined, clean_func(tkr, df1)), axis=1)
If you get:
TypeError: concat() got multiple values for argument 'axis'
Make sure your parentheses are correct per above.
With the code above, you can skip the original step:
df2 = clean_func(tkr,df1)
Since it is embedded in the concat function. Alternatively, you could keep the df2 step and use:
combined = pd.concat((combined,df2), axis=1)
Just make sure the dataframes are encapsulated by parentheses within the concat function.
CodePudding user response:
Same answer as GC123 but here is a full example which mimics reading from separate files and concatenating them
import pandas as pd
import io
fake_file_1 = io.StringIO("""
fruit,store,quantity,unit_price
apple,fancy-grocers,2,9.25
pear,fancy-grocers,3,100
banana,fancy-grocers,1,256
""")
fake_file_2 = io.StringIO("""
fruit,store,quantity,unit_price
banana,bargain-grocers,667,0.01
apple,bargain-grocers,170,0.15
pear,bargain-grocers,281,0.45
""")
fake_files = [fake_file_1,fake_file_2]
combined = pd.DataFrame()
for fake_file in fake_files:
df = pd.read_csv(fake_file)
df = df.set_index('fruit')
combined = pd.concat((combined, df), axis=1)
print(combined)
Output
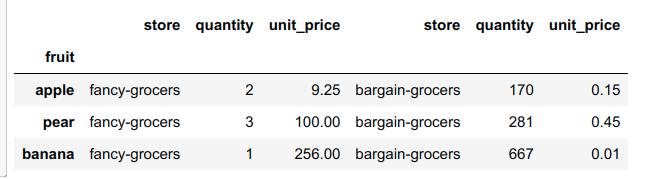
CodePudding user response:
This method is slightly more efficient:
combined = []
for fake_file in fake_files:
combined.append(pd.read_csv(fake_file).set_index('fruit'))
combined = pd.concat(combined, axis=1)
print(combined)
Output:
store quantity unit_price store quantity unit_price
fruit
apple fancy-grocers 2 9.25 bargain-grocers 170 0.15
pear fancy-grocers 3 100.00 bargain-grocers 281 0.45
banana fancy-grocers 1 256.00 bargain-grocers 667 0.01