I am running my PySpark data pipeline code on a standard databricks cluster. I need to save all Python/PySpark standard output and standard error messages into a file in an Azure BLOB account.
When I run my Python code locally I can see all messages including errors in the terminal and save them to a log file. How can something similar be accomplished with Databricks and Azure BLOB for PySpark data pipeline code? Can this be done?
Big thank you :)
CodePudding user response:
If you want to store error logs to azure storage account.
Please follow below steps:
1.Create a mount to azure blob Storage container, If you already have log file then store logs to mount location.
Access key
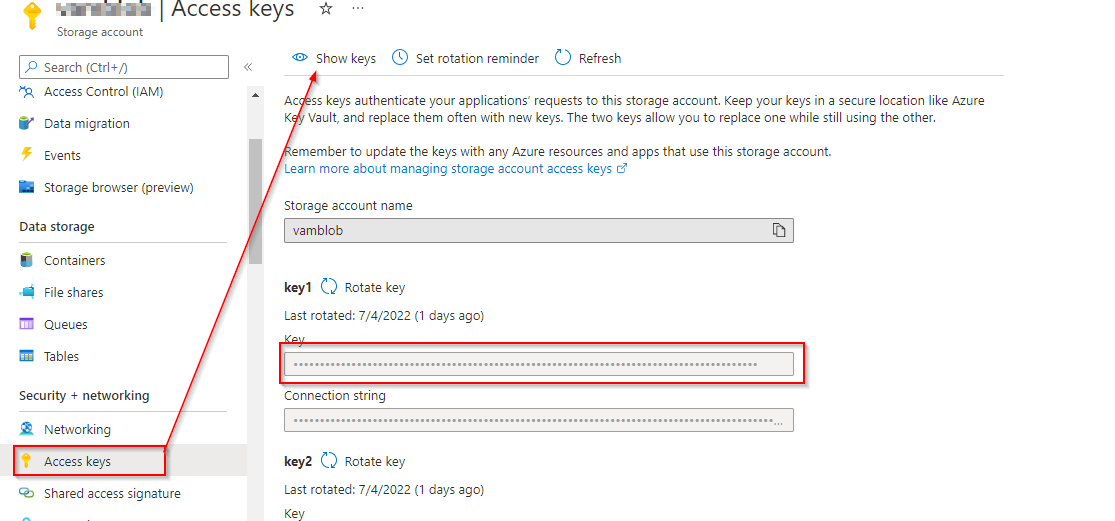
dbutils.fs.mount(
source = "wasbs://<container_name>@<storage_account_name>.blob.core.windows.net/",
mount_point = "/mnt/<mount_name>",
extra_configs = {"fs.azure.account.key.<storage_account_name>.blob.core.windows.net":"< storage_account_access key>})

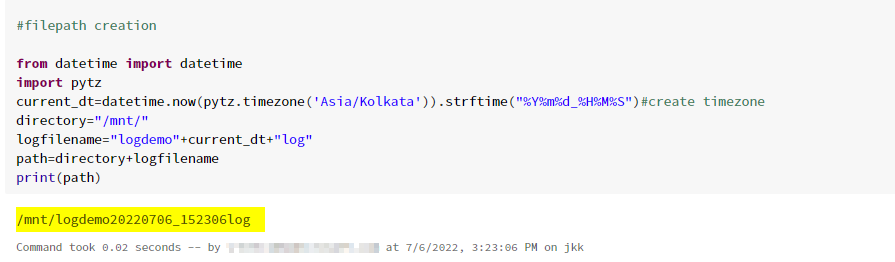
2.Filepath Creation
As per your requirement you can change time zone and save your file.(Example: IST, UST…etc.)
from datetime import datetime
import pytz
curr_dt=datetime.now(pytz.timezone('Asia/Kolkata')).strftime("%Y%m%d_%H%M%S")#create timezone
directory="/mnt/"
logfilename="<file_name>" curr_dt "log"
path=directory logfilename
print(path)
 3.File Handler
3.File Handler
import logging
logger = logging.getLogger('demologger')
logger.setLevel(logging.INFO)
FileHandler=logging.FileHandler(path,mode='a')
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s: %(message)s',datefmt='%m/%d/%Y %I:%M:%S %p')
FileHandler.setFormatter(formatter)
logger.addHandler(FileHandler)
logger.debug( 'debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical ('critical message')
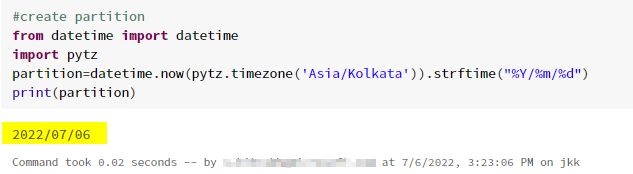
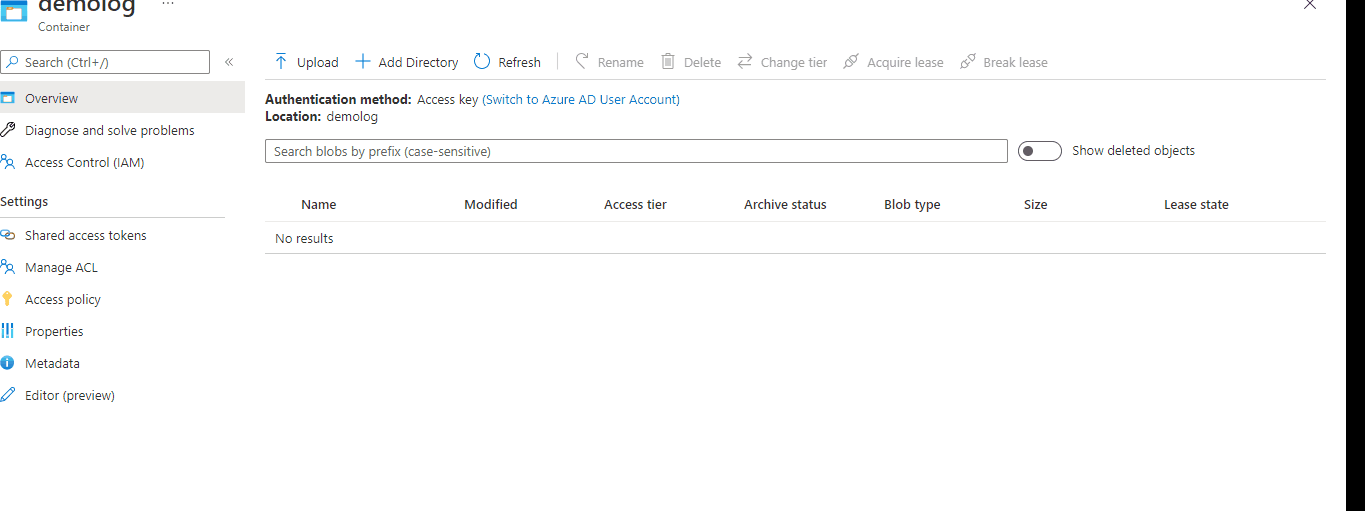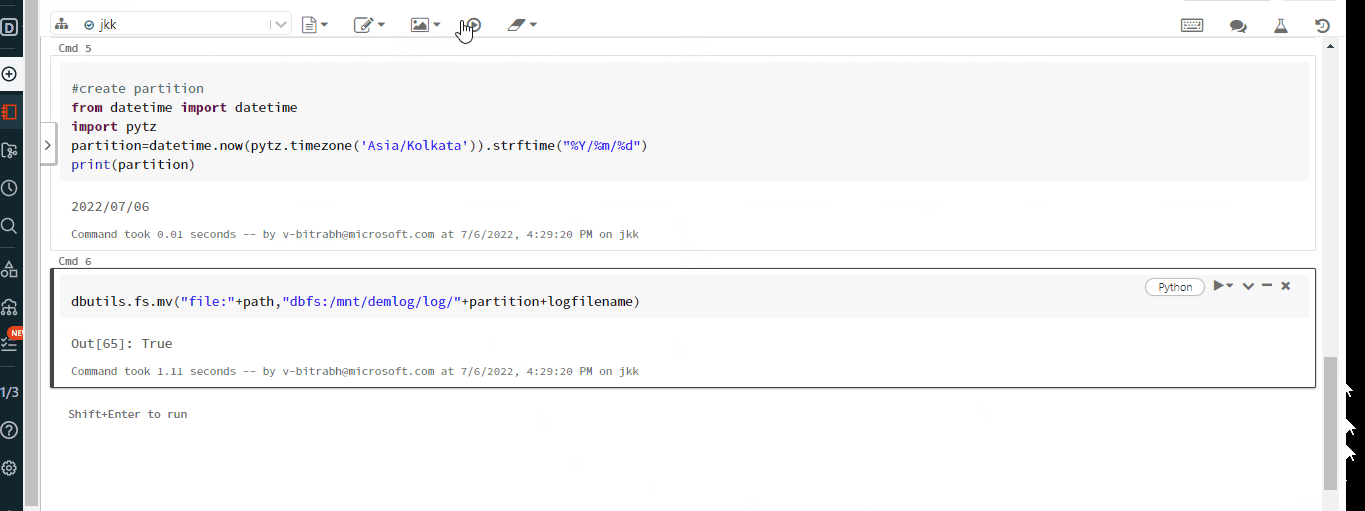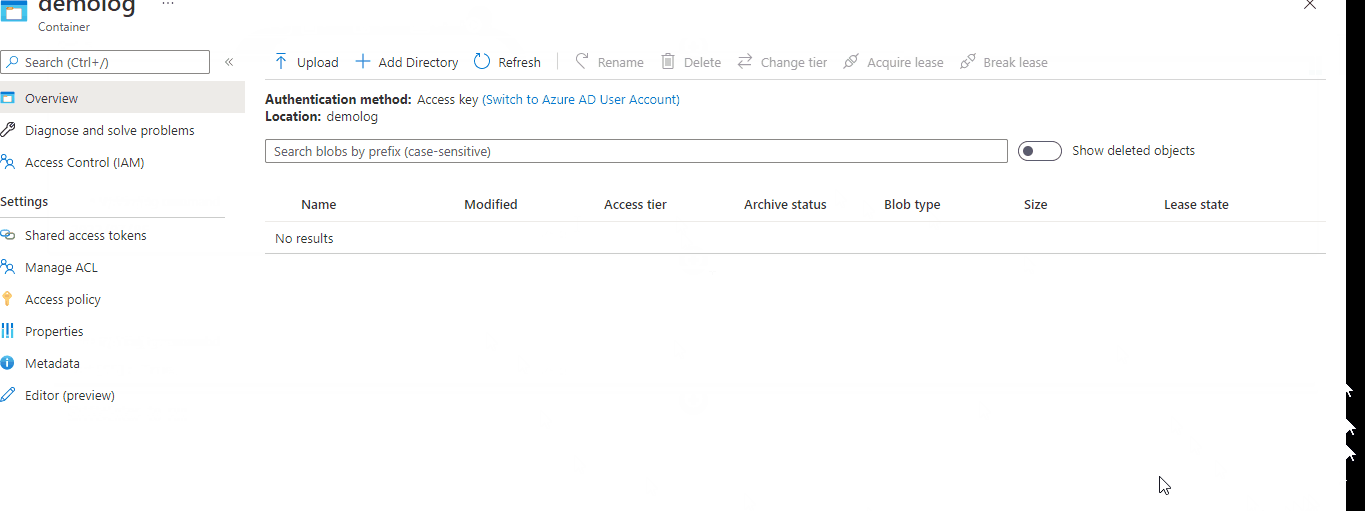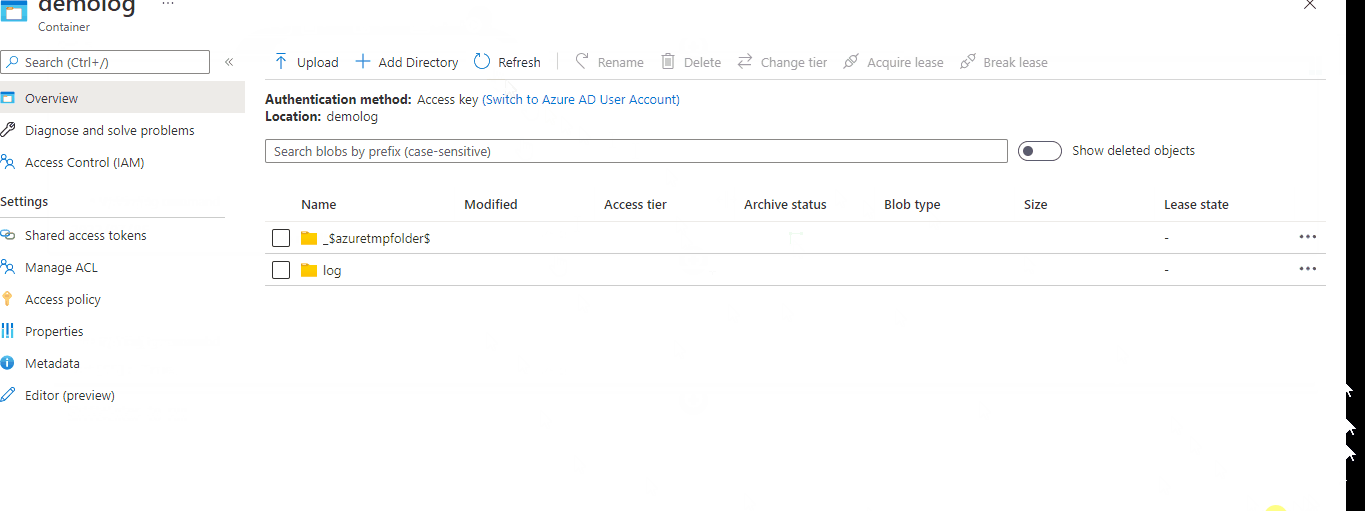
4.create partition
from datetime import datetime
import pytz
partition=datetime.now(pytz.timezone('Asia/Kolkata')).strftime("%Y/%m/%d")
print(partition)
5.Uploading Logs file Storage Account.
dbutils.fs.mv("file:" path,"dbfs:/mnt/<filelocation>/log/" partition logfilename)
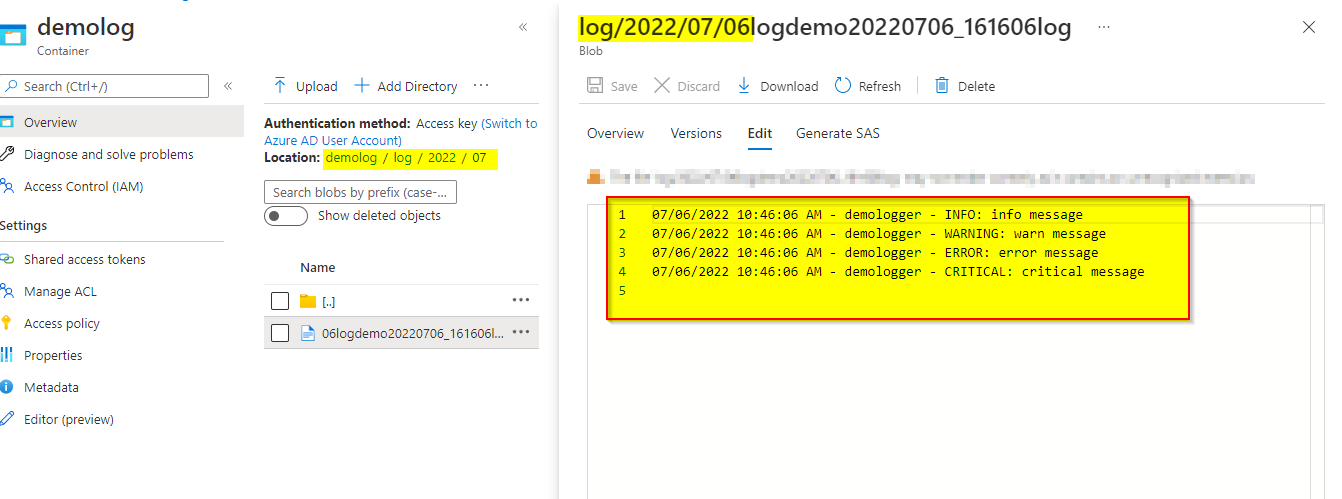
Output:
Reference:
Custom Logging in Databricks pyspark || Logging Strategies in Azure Databricks by Cloudpandith
Access Azure Blob storage using the azure DataBricks provide by microsoft.
CodePudding user response:
This is the approach I am currently taking. It is documented here: How to capture cell's output in Databricks notebook
from IPython.utils.capture import CapturedIO
capture = CapturedIO(sys.stdout, sys.stderr)
...
cmem = capture.stdout
I am writing the contents of cmem variable to a file in BLOB. BLOB is mounted to DBFS.