I am new to the concepts of typescript and Workshop in Palantir.
1) I would like to have the possibility to show the top GROUPs with a certain characteristic (for example the total AMOUNT). The GROUPs are more than 12,000 (thus exceeding the Palantir limit).
I try to specify: there are more than 12000 categories and i would the sum (for the column AMOUNT) of each categories!
Is there any way to avoid approximation of results and show the top 100 GROUPs (desc order) by amount? I wish I could do this both through the Pivot Table and through a Histogram. Also I would like to be able to show the correct sum of the amounts of the top 100 GROUPs (or, even better, the selected histogram bars).
2) Moreover .. on the histogram it is possible to select several bars at the same time (not 1 and not all)?!
3) Could I filter out who has less than a certain post aggregation value? (Not from the initial dataset but from the aggregation) Could I save a pivot output in an Object Set?!
I guess both questions are solvable through a function, could you kindly enter the TypeScript code to get what I would like?
Thank you!!
CodePudding user response:
You can do 1 and 3 in a transform instead of trying to do this aggregation in Quiver or Workshop directly on top of the objects. This will produce a pre-aggregated dataset that you can then create an object from. You'll then be able to use it in Workshop where you need the aggregation.
This is likely to work best for your data scale, as you mention you have 12000 buckets.
If you want to use a cut-off, the transform might look like:
from pyspark.sql import functions as F
from transforms.api import transform_df, Input, Output
@transform_df(
Output("/path/to/route_aggregation"),
source_df=Input("/path/to/flights"),
)
def compute(source_df):
return (
source_df
.groupBy(F.col("route_id"))
.agg(F.sum("distance").alias("total_distance_travelled"))
.filter(F.col("total_distance_travelled") > 500000)
)
or if you only want the top 100:
from pyspark.sql import functions as F, Window as W
from transforms.api import transform_df, Input, Output
@transform_df(
Output("/path/to/route_aggregation"),
source_df=Input("/path/to/flights"),
)
def compute(source_df):
return (
source_df
.groupBy(F.col("route_id"))
.agg(F.sum("distance").alias("total_distance_travelled"))
.withColumn("row_number", F.row_number().over(W.orderBy(F.col("total_distance_travelled").desc())))
.filter(F.col("row_number") <= 100)
)
If you are using write back on the objects, you should use the object's write back dataset to ensure the aggregations stay in sync with any edits you make via actions.
The downside of this approach is that you have to maintain another object type, and it's less flexible than the others (as to make a change you have to change the transform logic and potentially update your ontology definition. It also means there may be times the aggregations and individual object values are out of sync, as it takes time for the dataset to be updated. Additionally, these aggregation objects can clutter your ontology and aren't really 'objects' in the true sense.
One way you can avoid these downsides is if you can attach this aggregation to an existing object where it makes sense to do so. This works if you have ontology objects to represent the categories. For example, if you were grouping flights by route and then summing the distance travelled, rather than adding a new aggregation object you could just add a property to the route e.g. 'total distance travelled on route'.
CodePudding user response:
This may have issues if you are trying to aggregate into more than 1000 buckets. If your object set is larger than this (or expect it to be in the near future), use a different method.
You could create a Foundry Function in TypeScript to compute the aggregations, and then use this function to populate a Workshop table. For example to find the routes with the greatest total distance travelled along them (i.e. the group by property here is routeId and the summed property is distance):
import { Function, TwoDimensionalAggregation, BucketKey, BucketValue } from "@foundry/functions-api";
import { Objects, ExampleDataFlight } from "@foundry/ontology-api";
export class MyFunctions {
@Function()
public async aircraftAggregationExample(): Promise<TwoDimensionalAggregation<string>> {
const aggregation = await Objects.search().exampleDataFlight()
.filter(o => o.distance.range().gt(0))
.groupBy(o => o.routeId.topValues())
.sum(o => o.distance);
return sortBucketsByValue2D(aggregation, 'desc');
}
}
CodePudding user response:
This may have issues if you are trying to aggregate into more than 1000 buckets. If your object set is larger than this (or expect it to be in the near future), use a different method.
The easiest way to group and then sort on an aggregate in Workshop is to add a pivot table. It can be configured as follows:
- row grouping(s): category to group by
- aggregation(s): sum(AMOUNT)
and then pressing the dropdown on the aggregation column in the preview and pressing 'Sort descending'.
If you have a lot of data, you might get the error: "Too many values for , not all are displayed. Filter your data for more accurate results." In this case, you should either pre-filter your data if possible (e.g. remove irrelevant or zero values) or use one of the other approaches.
CodePudding user response:
If you want to aggregate lots of data with many categories into a histogram for filtering, you might want to consider using Contour instead of Workshop. The built-in 'Histogram' board seems ideal for this, for example:
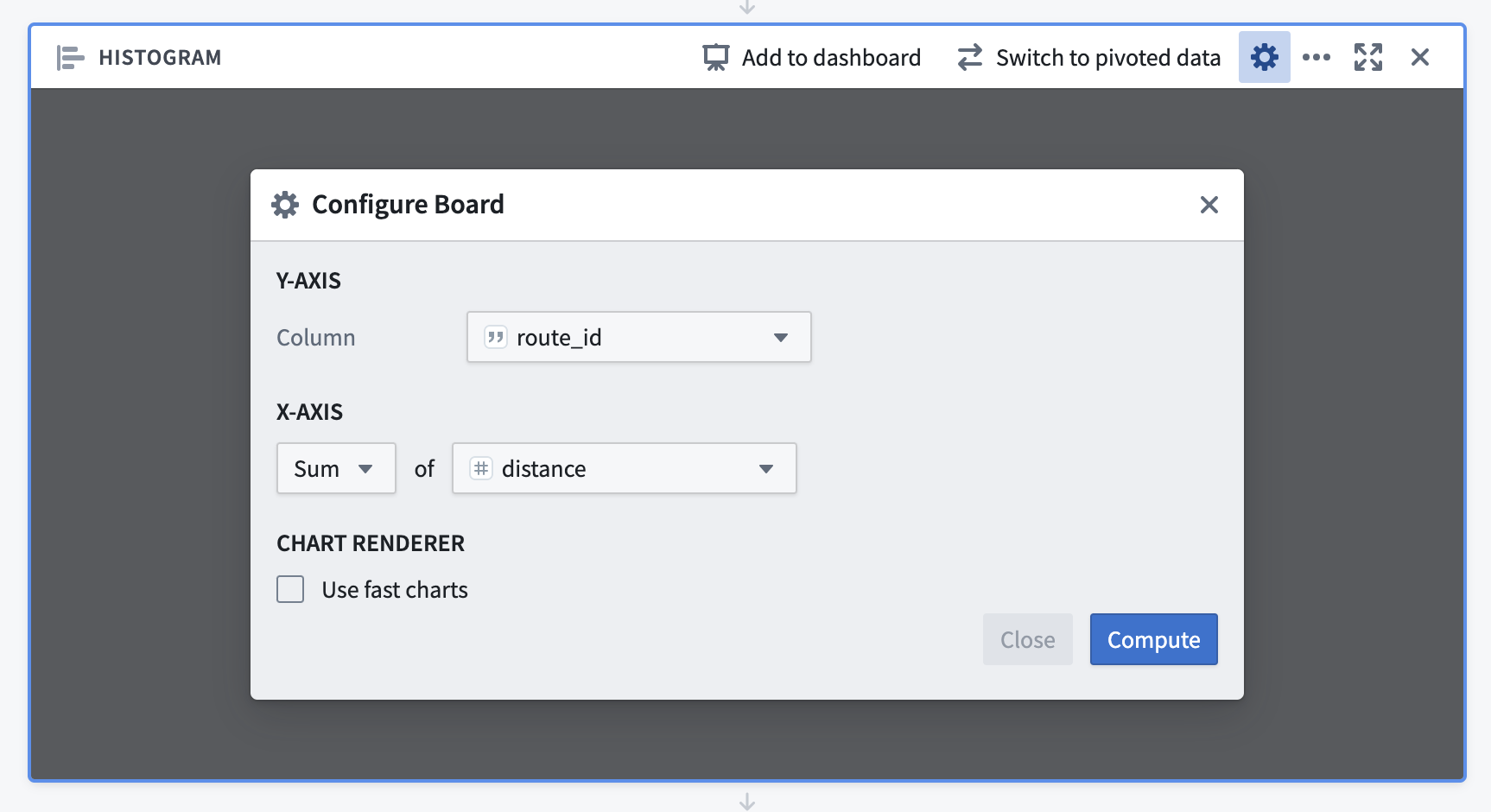
This will allow you to select multiple groups, and these filters are then applied to all boards beneath the Histogram board.
You can use Contour to create a dashboard, which can have similar functionality to some Workshop applications that don't require actions. You can also use Contour to build a pre-aggregated dataset (use the 'Switch to pivoted data' button and then 'Save as dataset' at the bottom) which can back an object to be used in Workshop.