| ID | Apples | Oranges |
|---|---|---|
| 1 | False | True |
| 1 | False | False |
| 2 | False | False |
| 3 | False | False |
| 3 | False | False |
| 4 | False | False |
| 5 | False | True |
| 5 | False | False |
The output I'm looking for in SQL
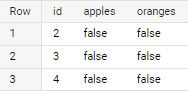
| ID | Apples | Oranges |
|---|---|---|
| 2 | False | False |
| 3 | False | False |
| 4 | False | False |
So what SQL query I would want to return is the two rows for ID 2,3 and 4 as they both only have False in Both categories.
Even though 1 & 5 has a False False combination it is not a distinct combination for that ID. (As they have another combination).
If I do
WHERE Grocery is False AND Confectionary is False then ID 1 and 5 also appear which is not what I want.
Any ideas on how I can do this in SQL?
We can assume the table name is called df.
CodePudding user response:
In ANSI SQL you would write:
select id, apples, oranges
from t
group by id, apples, oranges
having max(apples) = false
and max(oranges) = false
Basically you just need to check if the "greatest" value in each group is false.
CodePudding user response:
Use the NOT operand: