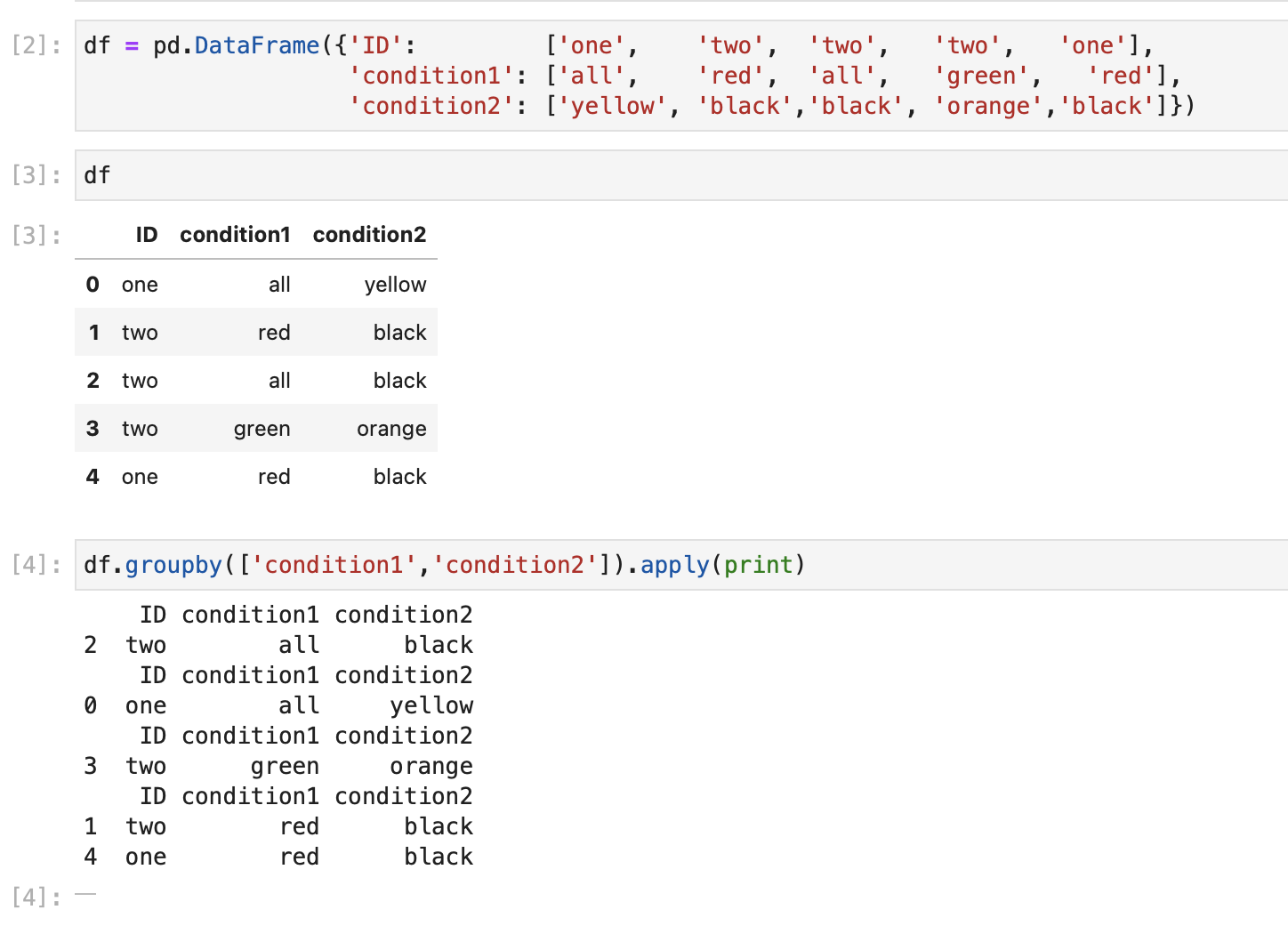
Is there any efficient way to groupby, but keeping a keyword value in all groups? For instance the word "all" belongs to every group instead of his own.
Such as:
df = pd.DataFrame({'ID': ['one', 'two', 'two', 'two', 'one'],
'condition1': ['all', 'red', 'all', 'green', 'red'],
'condition2': ['yellow', 'black','black', 'orange', 'all']})
df.groupby(['condition1','condition2']).apply(print)
So the row with ['all','black'] should be in the same group as ['red', 'black'], the expected output is :
ID condition1 condition2
0 one all yellow
ID condition1 condition2
2 two all black # here is the point of the problem
1 two red black
4 one red black
ID condition1 condition2
3 two green all
2 two all black # this row belongs to this group too
I tried to substitute 'all' for the set of the column and explode it, it does work, but is not efficient in real life dataframes.
Edit: now I realize there are some pathological behaviours defining the groups when they have the word "all". So it may be impossible to solve this question, without constraining the scope or the allowed groups.
CodePudding user response:
this is not a solution but might be helpful for you. you can pass a function in groupby instead of by. This function inputs an index and outputs a group based on a condition that you should define:
def your_func(idx):
#check the condition for df.loc[idx] and output a group like 'group1'
return the_correct_group
df.groupby(your_func).apply(print)
CodePudding user response:
I still don't know what is the problem. I use the same code you provided and get different result to your output