I am trying to develop an LSTM model using Keras, following 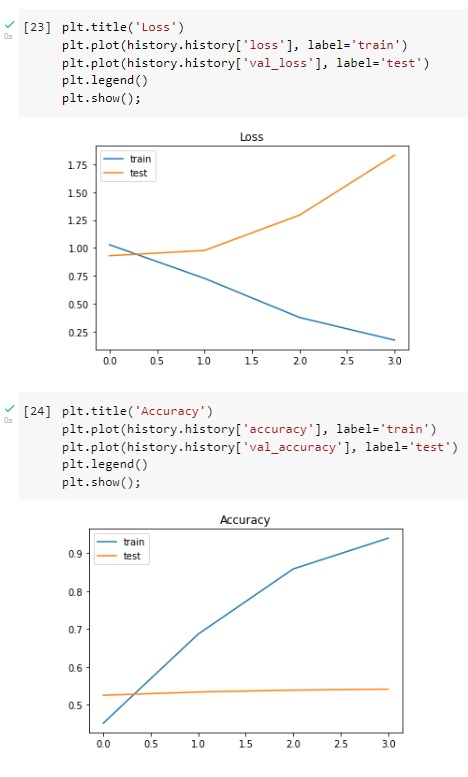
I tried to play around with different DropOut probabilities (i.e. 0.5 instead of 0.2), adding/removing hidden layers (and making them less dense), and decreasing/increasing the max number of words and max sequence length.
I have managed to get the graphs to align a bit more, however, that has led to the model having less accuracy with the training data (and the problem of overfitting is still bad):
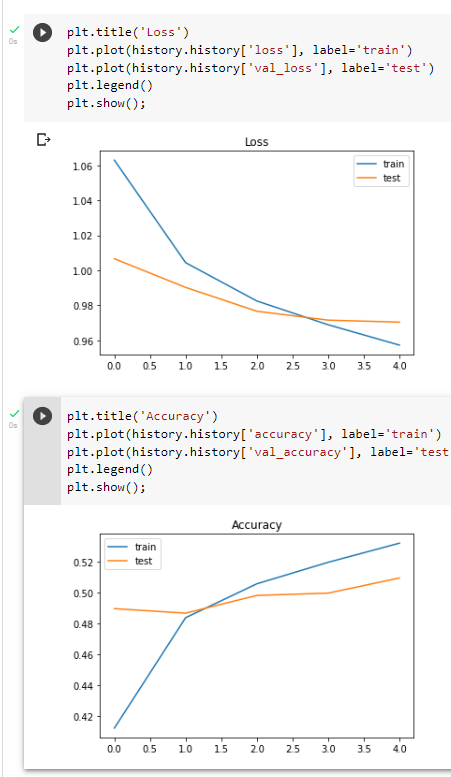
Additionally, I am not sure why the validation accuracy always seems to be higher than the model accuracy in the first epoch (shouldn't it usually be lower)?
Here is some code that is being used when tokenizing, padding, and initializing variables:
# The maximum number of words to be used. (most frequent)
MAX_NB_WORDS = 500
# Max number of words in each news article
MAX_SEQUENCE_LENGTH = 100 # I am aware this may be too small
# This is fixed.
EMBEDDING_DIM = 64
tokenizer = Tokenizer(num_words=MAX_NB_WORDS, filters='!"#$%&()* ,-./:;<=>?@[\]^_`{|}~',
lower=True)
tokenizer.fit_on_texts(df_raw['titletext'].values)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
X = tokenizer.texts_to_sequences(df_raw['titletext'].values)
X = pad_sequences(X, maxlen=MAX_SEQUENCE_LENGTH)
print('Shape of data tensor:', X.shape)
Y = pd.get_dummies(df_raw['label']).values
print('Shape of label tensor:', Y.shape)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size = 0.20)
print(X_train.shape,Y_train.shape)
print(X_test.shape,Y_test.shape)
X_train.view()
When I look at what is shown when X_train.view() is executed, I am also not sure why all the arrays start with zeros like this:

I also did a third attempt that was just a second attempt with the number of epochs increased, it looks like this:
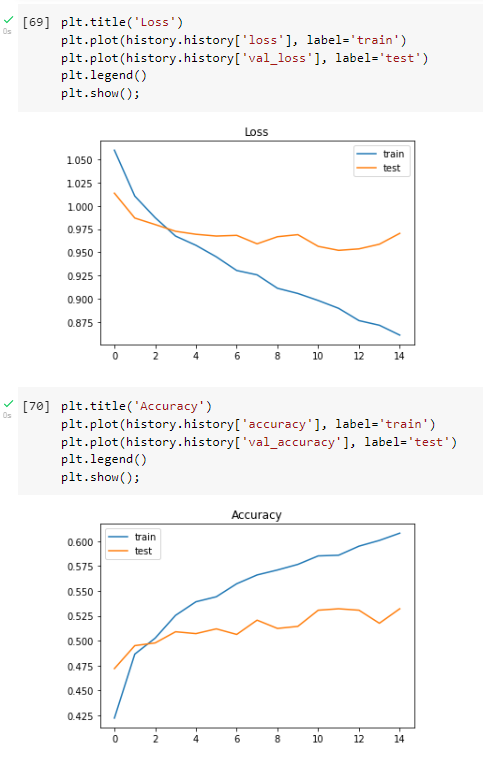
Here is the code of the actual model:
model = Sequential()
model.add(Embedding(MAX_NB_WORDS, EMBEDDING_DIM, input_length=X.shape[1]))
# model.add(SpatialDropout1D(0.2)) ---> commented out
# model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2)) ---> commented out
model.add(LSTM(64, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.5))
model.add(Dense(8))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
epochs = 25
batch_size = 64
history = model.fit(X_train, Y_train, epochs=epochs,
batch_size=batch_size,validation_split=0.2,callbacks=[EarlyStopping(monitor='val_loss', patience=3, min_delta=0.0001)])
Here is the link to the full code, including the dataset
Any help would be greatly appreciated!
CodePudding user response:
Hyperparameter adjustments for reducing overfitting in neural networks
Identify and ascertain overfitting. The first attempt shows largely overfitting, with early divergence of your test & train loss. I would try a lower learning rate here (in addition to the steps you took for regularisation with dropout layers). Using the default rate does not guarantee best results.
Allowing your model to find the global mimima / not being stuck in a local minima. On the second attempt, it looks better. However, if the x-axis shows the number of epochs -- it could be that your early stopping is too strict? ie. increase the threshold. Consider other optimisers, including SGD with a learning rate scheduler.
Too large network leads to overfitting on the trainset and difficulty in generalisation. Too many neurons may cause the network to 'memorize' all you trainset and overfit. I would try out 8, 16 or 24 neurons in your LSTM layer for example.
Data preprocessing & cleaning. Check your padding_sequences. It is probably padding the start of each text with zeros. I would pad post text.
Dataset. Depending on the size of your current dataset, I would suggest data augmentation to get to a sizable amount of text of training (empirically >=1M words). I would also try several techniques including feature engineering / improving data quality such as, spell checks. Are the classes imbalanced? You may need to balance them out by over/undersampling.
Consider using transfer learning and incorporate trained language models as your embeddings layer instead of training one from scratch. ie. https://www.gcptutorials.com/post/how-to-create-embedding-with-tensorflow