I have a dataset containing matrices with dimension of (3, 179) and used following NN model:
model = tf.keras.Sequential()
model.add(tf.keras.Input(shape=(13, 179)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256, activation = "relu", kernel_regularizer=tf.keras.regularizers.L2(0.001)))
# model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(256, activation = "relu", kernel_regularizer=tf.keras.regularizers.L2(0.001)))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(128, activation = "relu", kernel_regularizer=tf.keras.regularizers.L2(0.001)))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(32, activation = "relu", kernel_regularizer=tf.keras.regularizers.L2(0.01)))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(32, activation = "relu", kernel_regularizer=tf.keras.regularizers.L2(0.01)))
model.add(tf.keras.layers.Dense(8, activation = "relu", kernel_regularizer=tf.keras.regularizers.L2(0.01)))
model.add(tf.keras.layers.Dense(2, activation = "tanh", kernel_regularizer=tf.keras.regularizers.L2(0.01)))
model.add(tf.keras.layers.Dense(1, activation = "sigmoid"))
I used 80% data as training data, 10% for validation and 10% for testing.
The training loss curve and validation loss curve is not deviating that much but the validation loss curve very "zig-zag". You can se that in the following picture:
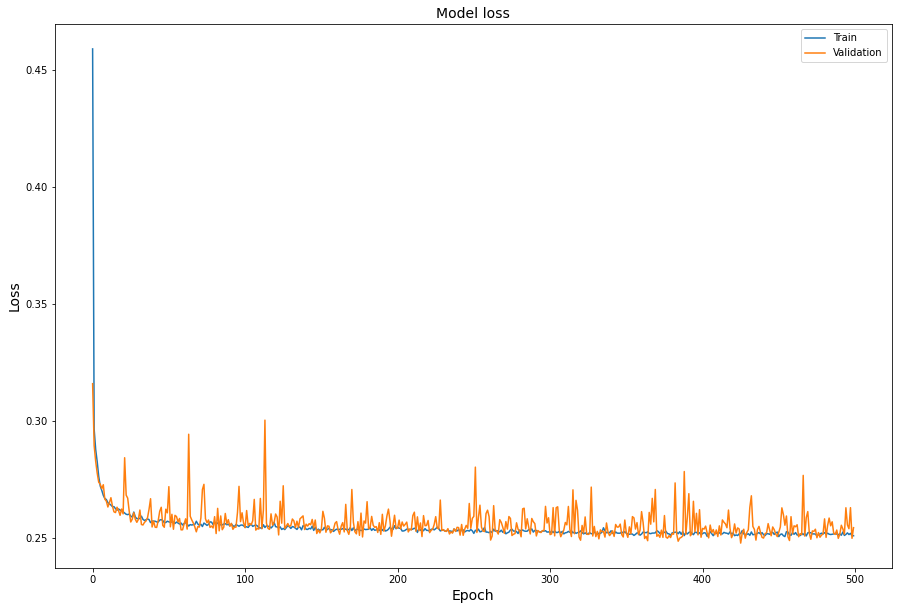
Can anyone tell me what I am doing wrong? More importantly why is this happening.
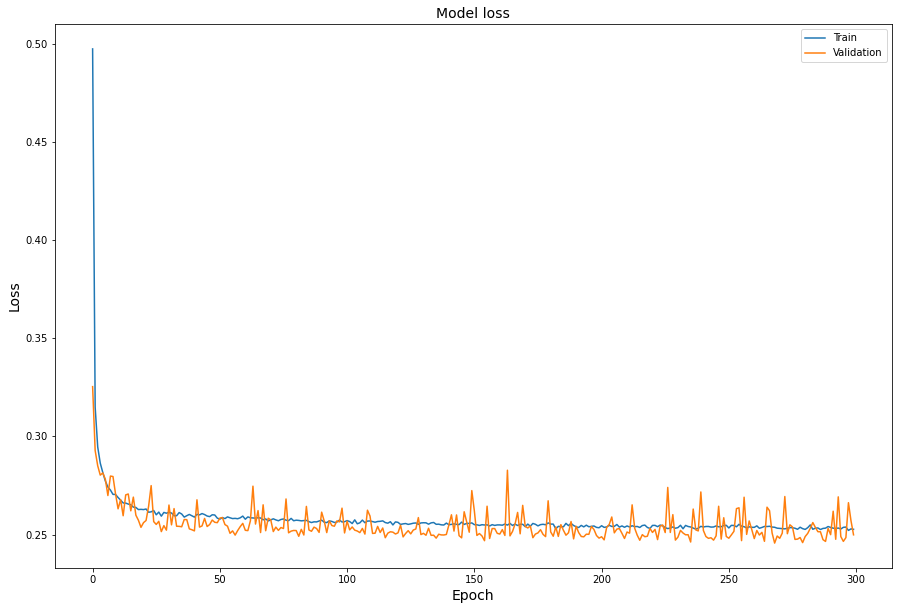
Added: As per the recommendation of first answer, I have used 25% data for validation. The result still looks kind of same.
CodePudding user response:
I guess this a statistical effect from the fact that you don't have enough validation data.
Having 10% of your data to validate your model is often not enough. The less validation data you have, the more "zig-zag" your validation loss will be. As randomness will have much more impact on your validation metrics.
In theory, I suggest you to use 70% for training data, 20% for validation data, 10% for testing data.
Why ?
Suppose you throw a dice. If you throw it 20 times, you might not been able to recognize the proper probabilities that is 1/6 for each face. But if you throw it 1000 times you will appreciate a much better approximation of the 1/6 probability for each face.
The validation process follows the same statistical low. If your validation data is not sufficient, you will end up with validation metrics that are far from reality.
CodePudding user response:
It looks like it's behaving like it's supposed to. Your second image looks less "zig-zag" than the previous one which is probably due to the expanded validation set. It's still going to zig zag to some extent though as validation images are not used to update the actual weights i.e. to train the model.