i have a list with dictionaries in which some dictionaries have a list of dictionaries too:
samples = [
{"person": "A", "employed": True, "location": "East",
"donations": []},
{"person": "B", "employed": False, "location": "West",
"donations": [
{"type": "cash", "date": "july 25, 2022", "value": 50},
{"type": "stocks", "date": "May 1, 2022", "value": 2500}
]},
{"person": "C", "employed": False, "location": "North",
"donations": []}
]
I wanted process this data to create a dataframe that has flattened the nested dictionaries and added new column headers like this:
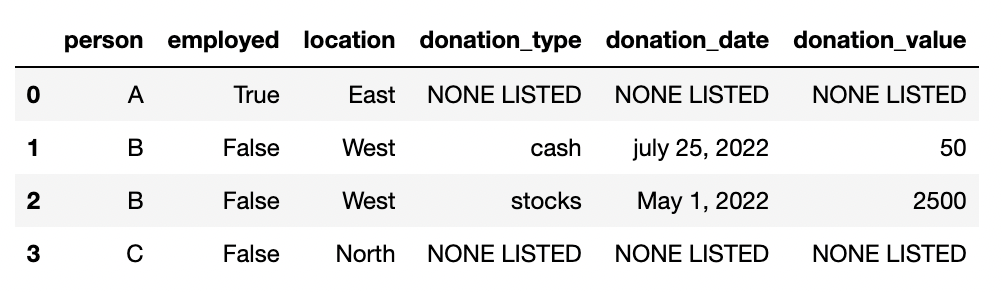
Here's the code that I have have, but it has a lot of repetition. What is an approach to make it more Pythonic and DRY:
data_list = [] ## initial empty list
for sample in samples:
## get data that is not nested
person = sample.get("person")
employed = sample.get("employed")
location = sample.get("location")
## if there is not nested data, give specific values
if len(sample.get("donations")) < 1:
donation_type = donation_date = donation_value = "NONE LISTED"
## build list
data_list.append({"person": person,
"employed": employed,
"location": location,
"donation_type": donation_type,
"donation_date": donation_date,
"donation_value": donation_value,
})
else:
## build same list but with provided values
donations = sample.get("donations")
for donation in donations:
data_list.append({"person": person,
"employed": employed,
"location": location,
"donation_type": donation.get("type"),
"donation_date": donation.get("date"),
"donation_value": donation.get("value")
})
CodePudding user response:
I like pandas.json_normalize for this because you don't need to supply the column names:
df = pd.DataFrame(samples).drop('donations', axis=1)
donations = pd.json_normalize(samples, record_path='donations', meta=['person'])
pd.merge(df, donations, how= 'left', on = 'person').apply(lambda x: x.fillna("NONE LISTED"))
Output:
person employed location type date value
0 A True East NONE LISTED NONE LISTED NONE LISTED
1 B False West cash july 25, 2022 50
2 B False West stocks May 1, 2022 2500
3 C False North NONE LISTED NONE LISTED NONE LISTED
CodePudding user response:
You can do:
df = pd.DataFrame(samples).explode('donations')
df_out = pd.concat([
df.drop('donations',axis=1),
df['donations'].apply(pd.Series).fillna('NONE LISTED')[['type', 'date', 'value']]],
axis=1)
#You can rename the columns after as needed.
print(df_out):
person employed location type date value
0 A True East NONE LISTED NONE LISTED NONE LISTED
1 B False West cash july 25, 2022 50.0
1 B False West stocks May 1, 2022 2500.0
2 C False North NONE LISTED NONE LISTED NONE LISTED
CodePudding user response:
A variant of the solution using only json_normalize:
dummy = [{"type": "NONE LISTED", "date": "NONE LISTED", "value": "NONE LISTED"}]
for sample in samples:
if not sample["donations"]:
sample["donations"] = dummy
res = pd.json_normalize(samples, "donations", ["person", "employed", "location"])
print(res)
Output
type date value person employed location
0 NONE LISTED NONE LISTED NONE LISTED A True East
1 cash july 25, 2022 50 B False West
2 stocks May 1, 2022 2500 B False West
3 NONE LISTED NONE LISTED NONE LISTED C False North