I am trying to fix this code where I'm trying to get table from SEC website of this company
Libraries:
# import our libraries
import requests
import pandas as pd
from bs4 import BeautifulSoup
Definition of parameters for search:
# base URL for the SEC EDGAR browser
endpoint = r"https://www.sec.gov/cgi-bin/browse-edgar"
# define our parameters dictionary
param_dict = {'action':'getcompany',
'CIK':'1265107',
'type':'10-k',
'dateb':'20190101',
'owner':'exclude',
'start':'',
'output':'',
'count':'100'}
# request the url, and then parse the response.
response = requests.get(url = endpoint, params = param_dict)
soup = BeautifulSoup(response.content, 'html.parser')
# Let the user know it was successful.
print('Request Successful')
print(response.url)
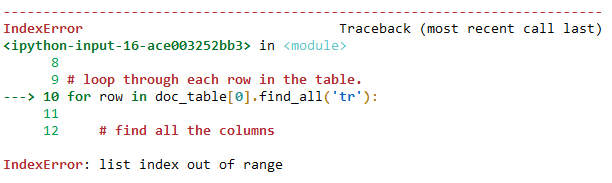
This is where the problem is, when I try to loop over the content of the table i get error shown below as if the table does not exist.
# find the document table with our data
doc_table = soup.find_all('table', class_='tableFile2')
# define a base url that will be used for link building.
base_url_sec = r"https://www.sec.gov"
master_list = []
# loop through each row in the table.
for row in doc_table[0].find_all('tr'):
The error:
Here is the link to the website I am trying to scrape https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=1265107&type=10-k&dateb=20190101&owner=exclude&start=&output=&count=100 When I inspect the elements of the website I can't find anything that could cause this error.
Thank you for any help.
CodePudding user response:
The following table data is static. You can grab the table using pandas without invoking the API url
import pandas as pd
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"
}
url= 'https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=1265107&type=10-k&dateb=20190101&owner=exclude&start=&output=&count=100'
req=requests.get(url,headers=headers).text
df=pd.read_html(req)[2]
print(df)
Output:
Filings Format ... Filing Date File/Film Number
0 10-K Documents Interactive Data ... 2018-03-07 333-11002518671437
1 10-K Documents Interactive Data ... 2017-03-13 333-11002517683575
2 10-K Documents Interactive Data ... 2016-03-08 333-110025161489854
3 10-K Documents Interactive Data ... 2015-03-06 333-11002515681017
4 10-K Documents Interactive Data ... 2014-03-04 333-11002514664345
5 10-K Documents Interactive Data ... 2013-03-01 333-11002513655933
6 10-K Documents ... 2006-09-20 333-110025061099734
7 10-K Documents ... 2005-09-23 333-110025051099353
[8 rows x 5 columns]
Alternative: Your code is also working fine. Just you have to inject the user-agent as headers.
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"
}
endpoint = r"https://www.sec.gov/cgi-bin/browse-edgar"
# define our parameters dictionary
param_dict = {'action':'getcompany',
'CIK':'1265107',
'type':'10-k',
'dateb':'20190101',
'owner':'exclude',
'start':'',
'output':'',
'count':'100'}
# request the url, and then parse the response.
response = requests.get(url = endpoint, params = param_dict,headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
# Let the user know it was successful.
print('Request Successful')
print(response.url)
doc_table = soup.find_all('table', class_='tableFile2')
# define a base url that will be used for link building.
base_url_sec = r"https://www.sec.gov"
master_list = []
# loop through each row in the table.
for row in doc_table[0].find_all('tr'):
print(list(row.stripped_strings))
Output:
['Filings', 'Format', 'Description', 'Filing Date', 'File/Film Number']
['10-K', 'Documents', 'Interactive Data', 'Annual report [Section 13 and 15(d), not S-K Item 405]', 'Acc-no: 0001265107-18-000013\xa0(34 Act)\xa0 Size: 11 MB', '2018-03-07', '333-110025',
'18671437']
['10-K', 'Documents', 'Interactive Data', 'Annual report [Section 13 and 15(d), not S-K Item 405]', 'Acc-no: 0001265107-17-000007\xa0(34 Act)\xa0 Size: 11 MB', '2017-03-13', '333-110025',
'17683575']
['10-K', 'Documents', 'Interactive Data', 'Annual report [Section 13 and 15(d), not S-K Item 405]', 'Acc-no: 0001265107-16-000052\xa0(34 Act)\xa0 Size: 9 MB', '2016-03-08', '333-110025', '161489854']