I have a scenario where I have to increment the timestamp of a column in my dataframe.
The dataframe consists of a a column which has a set of identical area IDs along with one "waterDuration" column.
I want to successively add this duration to the timestamp given in first row for each type of area and update the rest of the rows for each area ID incrementally.
This is how my dataframe looks like.
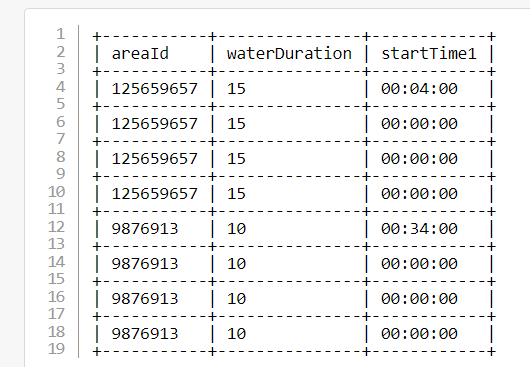
First timestamp for each areaId is given, I want to add whatever the duration is given next to it to the initial value and update and increment for the rest such as : -
These are all the columns of my dataframe :-
scheduleId int64
scheduleName object
areaId object
deviceId object
stationDeviceId object
evStatus object
waterDuration object
noOfCyles object
startTime1 object
startTime2 object
startTime3 object
startTime4 object
waterPlanning object
lastUpdatedTime object
dtype: object
I want all these columns and their values intact in the df along with the updated values in startTime1.
The value of waterDuration can change so I'd prefer not to use it directly in the solution. Any help would be great!!
CodePudding user response:
So here's your dataframe:
data = {
"areaID": ["125659657", "125659657", "125659657", "125659657", "9876913", "9876913", "9876913", "9876913"],
"waterDuration": ["15", "15", "15", "15", "10", "10", "10", "10"],
"startTime1": ["00:04:00", "00:00:00", "00:00:00", "00:00:00", "00:34:00", "00:00:00", "00:00:00", "00:00:00"]
}
df = pd.DataFrame(data)
You will need to change the dtypes:
df.waterDuration = df.waterDuration.astype(int)
In order to get the output you want, create a function to apply to the dataframe:
def add_from_last_row(row):
# If first row, nothing to do
# row.name corresponds to the DataFrame index
if row.name == 0:
return row.startTime1
# If prev. row is not the same area, do nothing
if row.areaID != df.loc[row.name-1, 'areaID']:
return row.startTime1
# Get the min index in order to get the original startTime
min_index = df[df.areaID == row.areaID].index.min()
# Here we get the original startTime, cast to datetime
default_time = pd.to_datetime(df.loc[min_index, 'startTime1'], format="%H:%M:%S")
# Sum all durations from min_index 1 to current row index
seconds_to_add = df.loc[min_index 1:row.name, 'waterDuration'].sum()
# Calculate the offset in seconds
offset = pd.DateOffset(seconds=int(seconds_to_add))
# return the last 8 character ie. hh:mm:ss
# otherwise it would be YYYY-MM-DD hh:mm:ss
return str(default_time offset)[-8:]
Then apply it:
df.apply(lambda x: add_from_last_row(x), axis=1)
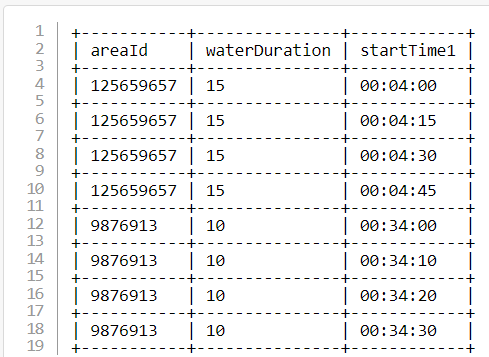
And the result:
0 00:04:00
1 00:04:15
2 00:04:30
3 00:04:45
4 00:34:00
5 00:34:10
6 00:34:20
7 00:34:30
dtype: object
Hope it helps !