I have made a TSQL script that pretty much takes/filters sets of data from a DB(multiple tables) and dump it on other table on a different DB. So far so good.
This is how the script looks like:
DECLARE @FechaInicio DATETIME = '2022-01-26 00:00:00.000';
DECLARE @FechaFin DATETIME = '2022-02-25 23:59:00.000'
WHILE (@FechaInicio <= @FechaFin)
BEGIN
PRINT '
;WITH CTE_CORTES AS (
SELECT
XX.PACIENTE_nVECES_REPETIDOS,
XX.FECHA_DEL_ESTUDIO,
XX.UNIDAD_TRATANTE,
XX.ApellidoPaterno,
XX.ApellidoMaterno,
XX.NOMBRE_DEL_PACIENTE,
XX.NSS,
XX.CLAVE_CPIM,
XX.AGREGADO_MEDICO,
XX.TIPO_DE_ESTUDIO,
XX.MODALIDAD,
XX.INTERPRETACION,
XX.PARTICION_UID
FROM
(
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY WW.UIDESTUDIO ORDER BY WW.FECHA_DEL_ESTUDIO) AS PARTICION_UID
FROM
(
SELECT
ROW_NUMBER() OVER(PARTITION BY (SUBSTRING(R.NSS,1,10)) ORDER BY R.FECHA_DEL_ESTUDIO) AS PACIENTE_nVECES_REPETIDOS,
R.UIDESTUDIO,
R.FECHA_DEL_ESTUDIO,
R.UNIDAD_TRATANTE,
R.ApellidoPaterno,
R.ApellidoMaterno,
R.NOMBRE_DEL_PACIENTE,
R.NSS,
R.CLAVE_CPIM,
R.AGREGADO_MEDICO,
R.TIPO_DE_ESTUDIO,
R.MODALIDAD,
CASE
WHEN R.RESULTADO IS NULL
THEN ''SIN INTERPRETACION''
ELSE CONVERT(VARCHAR, R.RESULTADO, 103)
END AS INTERPRETACION
FROM
(
SELECT
COUNT(T.UIDESTUDIO) AS VECES_REPETIDO,
*
FROM
(
SELECT
--ROW_NUMBER() OVER(ORDER BY FECHAESTUDIO) AS CONSECUTIVO,
E.IdPaciente,
E.FOLIO AS UIDESTUDIO,
CAST (E.FechaEstudio AS smalldatetime) AS FECHA_DEL_ESTUDIO,
''HGZ 98'' AS UNIDAD_TRATANTE,
P.ApellidoPaterno,
P.ApellidoMaterno,
CONCAT(P.PrimerNombre,'' '' /*COLLATE Modern_Spanish_CI_AI*/, P.SegundoNombre) AS NOMBRE_DEL_PACIENTE,
NSS = left(P.Folio replicate(''0'', 10), 10),
CASE
WHEN E.Modalidades=''CR''
THEN ''80.15.001''
WHEN E.Modalidades=''DX''
THEN ''80.15.001''
WHEN E.Modalidades=''MG''
THEN ''80.15.002''
WHEN E.Modalidades=''BDUS'' OR E.Modalidades=''BMD''
THEN ''80.15.003''
WHEN E.Modalidades=''RF''
THEN ''80.15.004''
WHEN E.Modalidades= ''US''
THEN (
CASE
WHEN E.Descripcion NOT LIKE ''%DOPPLER%'' /*OR E.Descripcion NOT LIKE ''%DOPLER%''*/ THEN ''80.15.005''
WHEN E.Descripcion LIKE ''%DOPPLER%'' OR E.Descripcion LIKE ''%DOPLER%'' THEN ''80.15.006''
ELSE ''80.15.005''
END )
WHEN E.Modalidades= ''CT''
THEN (
CASE
WHEN E.Descripcion NOT LIKE ''%CONTRAST%'' THEN ''80.15.007''
WHEN E.Descripcion LIKE ''%CONTRASTADO%'' /*OR E.Descripcion LIKE ''%GADOLIN%''*/ THEN ''80.15.008''
ELSE ''80.15.007''
END )
WHEN E.Modalidades=''MR''
THEN (
CASE
WHEN E.Descripcion NOT LIKE ''%CONTRASTADO%'' OR E.Descripcion NOT LIKE ''%GADOLIN%'' THEN ''80.15.009''
WHEN E.Descripcion LIKE ''%CONTRAST%'' OR E.Descripcion LIKE ''%GADOLIN%'' THEN ''80.15.010''
ELSE ''80.15.009''
END )
WHEN E.Modalidades=''XA''
THEN ''80.15.011''
WHEN E.Modalidades = ''ES''
THEN ''80.15.012''
ELSE ''80.15.014''
END AS CLAVE_CPIM,
AGREGADO_MEDICO = LEFT(SUBSTRING(P.Folio,11,18) REPLICATE(''0'',8),8),
CASE
WHEN E.Modalidades=''CR''
THEN ''Radiología Simple''
WHEN E.Modalidades=''DX''
THEN ''Radiología Simple''
WHEN E.Modalidades=''MG''
THEN ''Mastografía''
WHEN E.Modalidades=''BDUS'' OR E.Modalidades=''BMD''
THEN ''Densitometría''
WHEN E.Modalidades=''RF''
THEN ''Radiología Contrastada''
WHEN E.Modalidades=''US''
THEN (
CASE
WHEN E.Descripcion NOT LIKE ''%DOPPLER%'' /*OR E.Descripcion NOT LIKE ''%DOPLER%''*/ THEN ''Ultrasonido''
WHEN E.Descripcion LIKE ''%DOPPLER%'' OR E.Descripcion LIKE ''%DOPLER%'' THEN ''Ultrasonido Doppler''
ELSE ''Ultrasonido''
END )
WHEN E.Modalidades=''CT''
THEN (
CASE
WHEN E.Descripcion NOT LIKE ''%CONTRAST%'' THEN ''Tomografía Computada Simple''
WHEN E.Descripcion LIKE ''%CON CONTRASTE%'' OR E.Descripcion LIKE ''%CONTRASTADO%'' OR E.Descripcion LIKE ''%CONTRASTADA%'' OR E.Descripcion LIKE ''%GADOLIN%'' THEN ''Tomografía Computada con medio de Contraste''
ELSE ''Tomografía Computada Simple''
END )
WHEN E.Modalidades=''MR''
THEN (
CASE
WHEN E.Descripcion NOT LIKE ''%CONTRAST%'' THEN ''Resonancia Magnética Simple''
WHEN E.Descripcion LIKE ''%CON CONTRAST%'' OR E.Descripcion LIKE ''%CONTRASTADO%'' OR E.Descripcion LIKE ''%CONTRASTADA%'' OR E.Descripcion LIKE ''%GADOLIN%'' THEN ''Resonancia Magnética Contrastada''
ELSE ''Resonancia Magnética Simple''
END )
WHEN E.Modalidades=''XA''
THEN ''RADIOLOGIA INTERVENCIONISTA VASCULAR''
WHEN E.Modalidades=''ES''
THEN ''RADIOLOGIA INTERVENCIONISTA NO VASCULAR''
ELSE ''OTRAS MODALIDADES DICOM''
END AS TIPO_DE_ESTUDIO,
E.Modalidades AS MODALIDAD,
CASE
WHEN I_R_E.IdEstadoResultado IN (0,1,2)
THEN ''SIN INTERPRETACION''
ELSE CONVERT(VARCHAR,I_R_E.FechaResultado,103)
END AS RESULTADO
FROM
DBO.Pacientes AS P
INNER JOIN
DBO.ImagenologiaEstudios AS E ON P.IDPACIENTE=E.IdPaciente
LEFT JOIN
dbo.ImagenologiaResultadosEstudio AS I_R_E ON E.IdEstudio=I_R_E.IdEstudio AND E.IdEstudio=I_R_E.IdEstudio
WHERE
E.FechaEstudio BETWEEN ' '''' CONVERT(VARCHAR,@FechaInicio,121) '''' ' AND ' '''' CONCAT(CONVERT(VARCHAR,@FechaInicio,23),' 23:59:59.999') '''' ' AND E.VisiblePACS = 1
) AS T
GROUP BY
T.IdPaciente,
T.UIDESTUDIO,
T.FECHA_DEL_ESTUDIO,
T.UNIDAD_TRATANTE,
T.ApellidoPaterno,
T.ApellidoMaterno,
T.NOMBRE_DEL_PACIENTE,
T.NSS,
T.CLAVE_CPIM,
T.AGREGADO_MEDICO,
T.TIPO_DE_ESTUDIO,
T.MODALIDAD,
T.RESULTADO
HAVING
COUNT(T.UIDESTUDIO) >= 1
) AS R
) AS WW
) AS XX
)
INSERT INTO HIS_CORTES_UDDCM.dbo.CORTE_MES_EJEMPLO (
[PACIENTE_nVECES_REPETIDOS],[FECHA_DEL_ESTUDIO],[UNIDAD_TRATANTE],[ApellidoPaterno],[ApellidoMaterno],[NOMBRE_DEL_PACIENTE],[NSS],[CLAVE_CPIM],[AGREGADO_MEDICO],[TIPO_DE_ESTUDIO],[MODALIDAD],[INTERPRETACION],[PARTICION_UID])
SELECT
TOP 1000 [PACIENTE_nVECES_REPETIDOS],[FECHA_DEL_ESTUDIO],[UNIDAD_TRATANTE],[ApellidoPaterno],[ApellidoMaterno],[NOMBRE_DEL_PACIENTE],[NSS],[CLAVE_CPIM],[AGREGADO_MEDICO],[TIPO_DE_ESTUDIO],[MODALIDAD],[INTERPRETACION],[PARTICION_UID]
FROM
CTE_CORTES
WHERE
CTE_CORTES.PARTICION_UID=1
ORDER BY
CTE_CORTES.NSS, CTE_CORTES.FECHA_DEL_ESTUDIO'
SET @FechaInicio = 1
PRINT '/*#######################################################################################SALTO DE DIA#######################################################################################*/'
END
The whole script relies on a line of code that pretty much partitions sets of data(I'm using ROW_NUMBER and nesting the SUBSTRING function) and the ordering of the IDs and date is taken cared of by the ORDER BY clause(which is as importat as the ROW_NUMBER window function).
This is the line I'm refering to:

What this does is basically takes the ID column(string) and goes up to 10 characters. If there are similarities between the first 10 characters among the ID column rows, then the ROW_NUMBER function groups/enumerates each row from 1 up to number of coincidences found within a single day(It cannot go beyond a day. Because if it does, data are not longer reliable. That's the reason why the script above inserts data day by day by using the WHILE loop).
This is how the table looks like after executing the TSQL script:
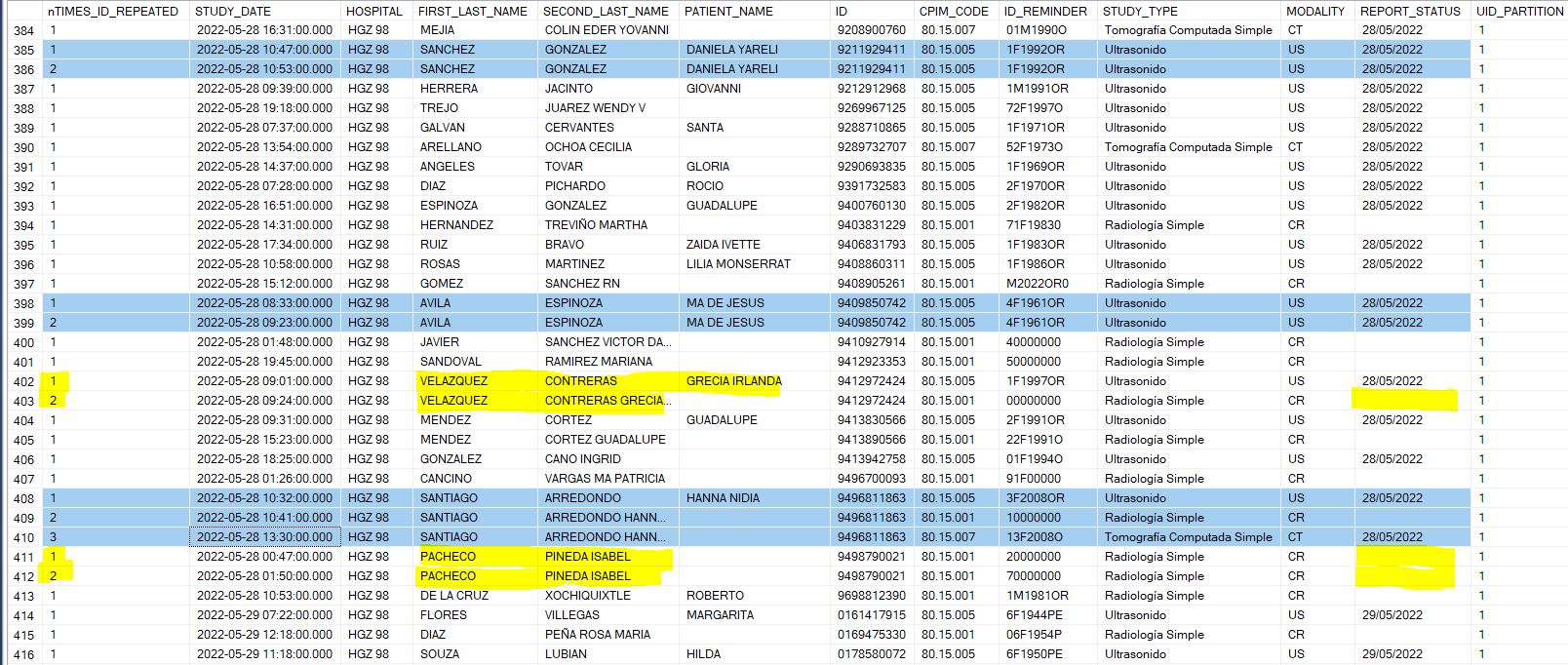
If you pay close attention to the first column and the rows highlighted in blue, you'll see the partitioning/grouping by sets I was talking about being performed. Rows and IDs have been sorted/ordered by date and ID(ascending) in an organized manner. Similarities between the IDs are being displayed in the nTIMES_ID_REPEATED column. The main focus is on the rows highlighted in blue. Those are the ones that meet the criteria I'm about to explain. The ones highlighted in yellow also meet the criteria(similarities) but cannot be taken into account since their respective REPORT_STATUS column(Date type) are empty.
Now, this is where it gets challenging(and honestly, I have no idea how to tackle this challenge). Based on the partitioning/grouping that has been done with the nTIMES_ID_REPEATED column, I've been tasked to access those rows(the ones that display 1, 2, 3, up to the last number) and perform(maybe) another window function to list them again(display them on a different column) as long as their respective REPORT_STATUS column is not empty.
This is how the desired result should look like:
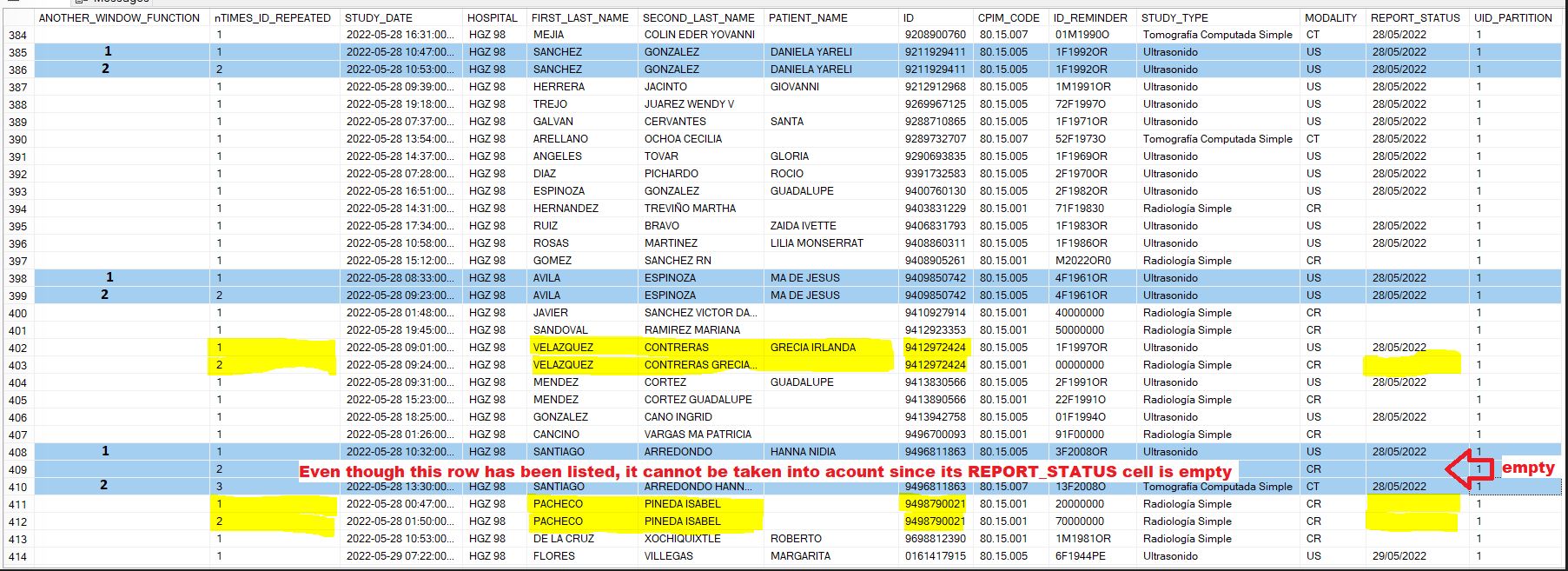
Eventhough the ROW_COUNT together with theSUBSTRING function have found more matches(nTIMES_ID_REPEATED column), the rows in yellow cannot be taken into account since its REPORT_STATUS column are empty. Basically they should be ignored.
By the way, I made a dummy table and populated it with the very same challenge for those who want to give it a try at 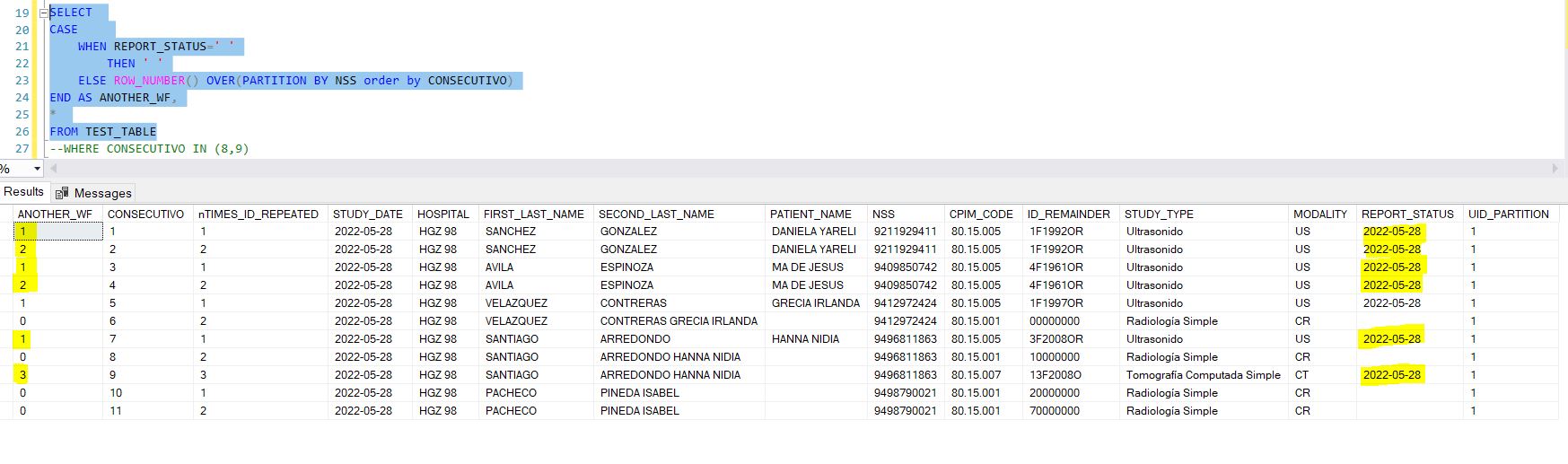
CodePudding user response:
I believe these would both work. You might find that one performs better than the other:
case when report_status <> '' then
row_number() over (
partition by <ID>
-- push the nulls out to the end so they don't interfere with numbering
order by case when report_status <> '' then 0 else 1 end, <date>) end
Or
case when report_status <> '' then
row_number() over (
-- move the null rows into a distinct partition
partition by <ID>, case when report_status <> '' then 1 end
order by <date>) end
It seems that your column may be a varchar(255) rather than a date. Replace the null checks with whatever test is appropriate for your logic.