Problem
I want to remove some surrounding text from strings in a dataframe.
Reprex
What I have
df1 = pd.DataFrame({'a': [1, 1, 2, 2, 3],
'b': ["NOSE PARKER Bond 1 Spain", "Fire PA1KER Bond 10 UK",
"NOSE 2HANDS Bond 3 FRANCE", "EARS STARKER Bond 11 SOUTH AFRICA",
"NORSEPACKER Bond 01 JAPAN2002"],
'c': [13, 9, 12, 5, 5]})
df1

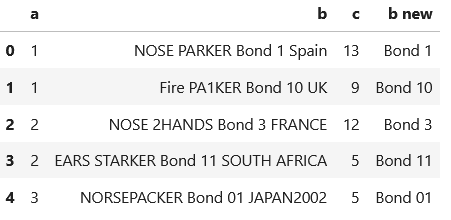
What I want
df2 = pd.DataFrame({'a': [1, 1, 2, 2, 3],
'b': ["NOSE PARKER Bond 1 Spain", "Fire PA1KER Bond 10 UK",
"NOSE 2HANDS Bond 3 FRANCE", "EARS STARKER Bond 11 SOUTH AFRICA",
"NORSEPACKER Bond 01 JAPAN2002"],
'c': [13, 9, 12, 5, 5],
'b new': ["Bond 1", "Bond 10", "Bond 3", "Bond 11", "Bond 01"]})
df2
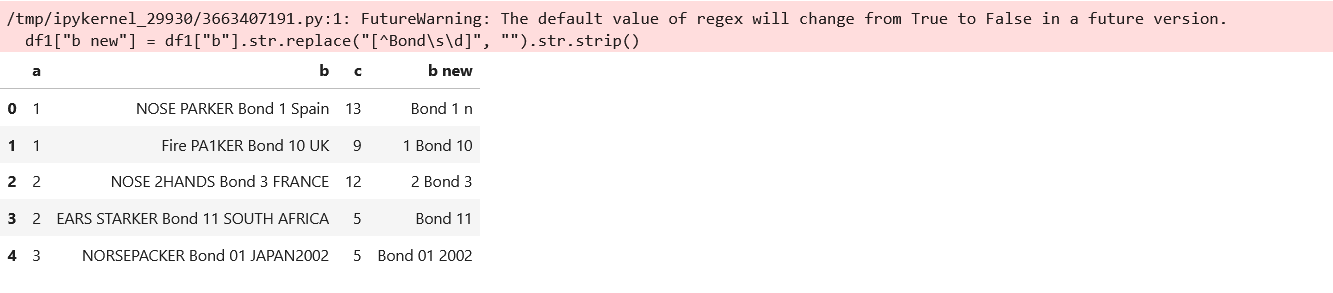
My Attempt
df1["b new"] = df1["b"].str.replace("[^Bond\s\d]", "").str.strip()
df1
CodePudding user response:
you can use extract method to get required format.As per below regex there will be a space before bond and space before digit and digit can be one or more.
df['b_new'] = df.b.str.extract('( Bond \d )')
Result:
a b c b_new
0 1 NOSE PARKER Bond 1 Spain 13 Bond 1
1 1 Fire PA1KER Bond 10 UK 9 Bond 10
2 2 NOSE 2HANDS Bond 3 FRANCE 12 Bond 3
3 2 EARS STARKER Bond 11 SOUTH AFRICA 5 Bond 11
4 3 NORSEPACKER Bond 01 JAPAN2002 5 Bond 01