I am trying to write a short python program to download of copy of the xml jail roster for the local county save that that file, scrape and save all the names and image links in a csv file, then download each of the photos with the file name being the name.
I've managed to get the XML file, save it locally, and create the csv file. I was briefly able to write the full xml tag (tag and attribute) to the csv file, but can't seem to get just the attribute, or the image links.
from datetime import datetime
from datetime import date
import requests
import csv
import bs4 as bs
from bs4 import BeautifulSoup
# get current date
today = date.today()
# convert date to date-sort format
d1 = today.strftime("%Y-%m-%d")
# create filename variable
roster = 'jailroster' '-' d1 '-dev' '.xml'
# grab xml file from server
url = "https://legacyweb.randolphcountync.gov/sheriff/jailroster.xml"
print("ATTEMPTING TO GET XML FILE FROM SERVER")
req_xml = requests.get(url)
print("Response code:", req_xml.status_code)
if req_xml.status_code == 200:
print("XML file downloaded at ", datetime.now())
soup = BeautifulSoup(req_xml.content, 'lxml')
# save xml file from get locally
with open(roster, 'wb') as file:
file.write(req_xml.content)
print('Saving local copy of XML as:', roster)
# read xml data from saved copy
infile = open(roster,'r')
contents = infile.read()
soup = bs.BeautifulSoup(contents,'lxml')
# variables needed for image list
images = soup.findAll('image1')
fname = soup.findAll('nf')
mname = soup.findAll('nm')
lname = soup.findAll('nl')
baseurl = 'https://legacyweb.randolphcountync.gov/'
with open('image-list.csv', 'w', newline='') as csvfile:
imagelist = csv.writer(csvfile, delimiter=',')
print('Image list being created')
imagelist.writerows(images['src'])
I've gone through about a half dozen tutorials trying to figure all this out, but I think this is the edge of what I have been able to learn so far and I haven't even started to try and figure out how to save the list of images as files. Can anyone help out with a pointer or two or point me towards tutorials on this?
Update: No this is not for a mugshot site or any unethical purposes. This data is for a private data project for a non-public public safety project.
CodePudding user response:
This should get you the data you need:
from datetime import date
import requests
from bs4 import BeautifulSoup
import pandas as pd
def extractor(tag: str) -> list:
return [i.getText() for i in soup.find_all(tag)]
url = "https://legacyweb.randolphcountync.gov/sheriff/jailroster.xml"
soup = BeautifulSoup(requests.get(url).text, features="lxml")
images = [
f"{'https://legacyweb.randolphcountync.gov'}{i['src'].lstrip('..')}"
for i in soup.find_all('image1')
]
df = pd.DataFrame(
zip(extractor("nf"), extractor("nm"), extractor("nl"), images),
columns=['First Name', 'Middle Name', 'Last Name', 'Mugshot'],
)
df.to_csv(
f"jailroster-{date.today().strftime('%Y-%m-%d')}-dev.csv",
index=False,
)
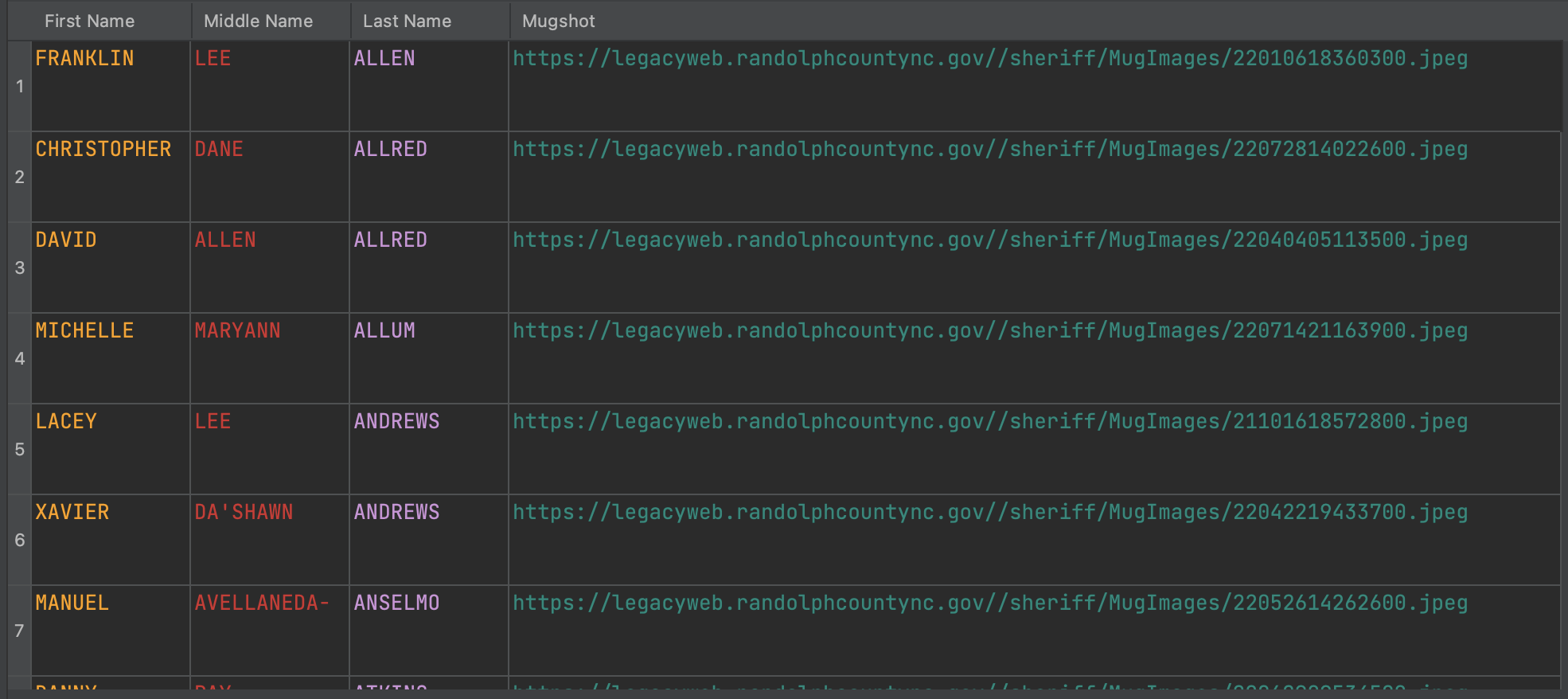
Sample output (a .csv file):