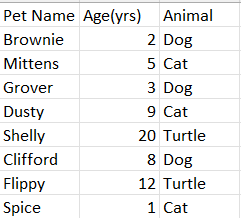
Im trying to group rows of data in a .xlsx file(see image) by Animal and then get a list of Pet Names that meet one condition: Age(yrs) is greater than the mean Age(yrs) of Animal group. Current Code: import pandas as pd df = pd.read_excel('pets.xlsx')
above_avg = []
animal = df.groupby('Animal')
avg_age = animal.mean()
for index, row in df.iterrows():
if row['Age(yrs)'] > avg:
above_avg.append(row['Pet Name'])
print(above_avg)
Output (error):
if row['Age(yrs)'] > avg:
f"The truth value of a {type(self).__name__} is ambiguous. "
ValueError: The truth value of a DataFrame is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all()
How can I correct this error in my code so that I get the desired output?:
['Dusty', 'Clifford', 'Shelly']
CodePudding user response:
Your method is correct but you 're not using the proper column for calculating mean. This should fix the problem
above_avg = []
animal = df.groupby('Animal')
avg_age = animal['Age(yrs)'].mean()
for index, row in df.iterrows():
if row['Age(yrs)'] > avg_age[row['Animal']]:
above_avg.append(row['Pet Name'])
print(above_avg)