I'm trying to populate left to right table.
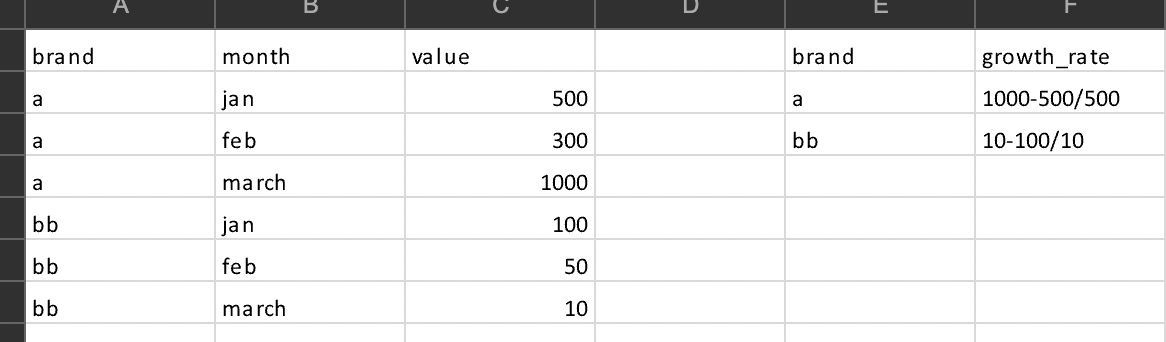
I was trying to get min and max (month) by group by brand and then get's it's value according to the month.
select
brand
,month
,value
from table
where month=max(month) or month=min(month)
not sure how to do it in a efficient way.
CodePudding user response:
First you need to have month as an integer.
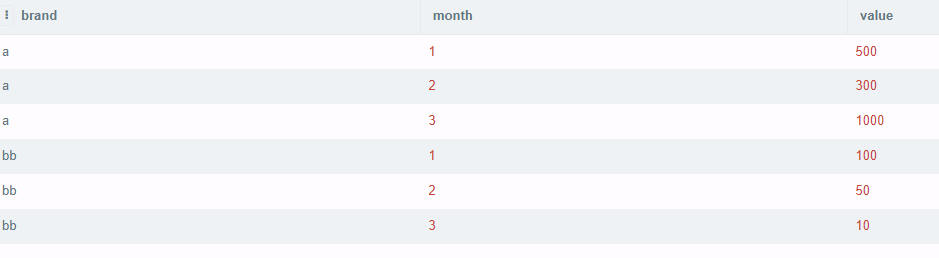
After that you need to join two times the same table with itself in order to get the value for the min and max months by brand.
select a.*, b.value as value_max_month, c.value as value_min_month
from(
select
brand, max(month) as max_month, min(month) as min_month
from table1
group by brand) as a
left join table1 as b on a.max_month = b.month and a.brand = b.brand
left join table1 as c on a.min_month = c.month and a.brand = c.brand
Output:

CodePudding user response:
If you want to avoid joins, you can calculate the min and max using window function.
spark.sql('''
select brand, mth, val from (
select *,
min(mth_int) over (partition by brand) as min_mth_int,
max(mth_int) over (partition by brand) as max_mth_int
from(
select *, month(coalesce(to_date(initcap(mth), "MMM"), to_date(initcap(mth), "MMMM"))) as mth_int
from data))
where mth_int=min_mth_int or mth_int=max_mth_int
'''). \
show()
# ----- ----- ----
# |brand| mth| val|
# ----- ----- ----
# | a| jan| 500|
# | a|march|1000|
# ----- ----- ----
P.S. the month() function used here will not be available in Redshift, and you can use its extract() function to get the month. There might be a slight difference in Redshift's to_date() function as well.