I have a dataframe that loads data from a python list of jsons.
df = spark.read\
.option("inferSchema","true")\
.option("multiline",True)\
.json(sc.parallelize(array_json))
The json structure can look like this:
{
"name" : "Alex"
"value" : 2,
"tag" : {
"property1" : "value1"
}
}
But also it can look like this:
{
"name" : "Robert"
"value" : 2,
"tag" : None
}
As you can see, the property tag can be a json or a null value.
The problem I'm having is that I'm getting a column called _corrupt_record only for the json values that have the tag value as None.
| _corrupt_record | name | value | tag |
|---|---|---|---|
| null | Alex | 2 | {"property1":"value1"} |
| {"name":"Robert","value":2,"tag":None | null | null | null |
I want the dataframe to be like the following:
| name | value | tag |
|---|---|---|
| Alex | 2 | {"property1":"value1"} |
| Robert | 2 | None |
Any ideas on how to solve this?
CodePudding user response:
I reproduced this and faced same issue with the JSON data that you have provided.
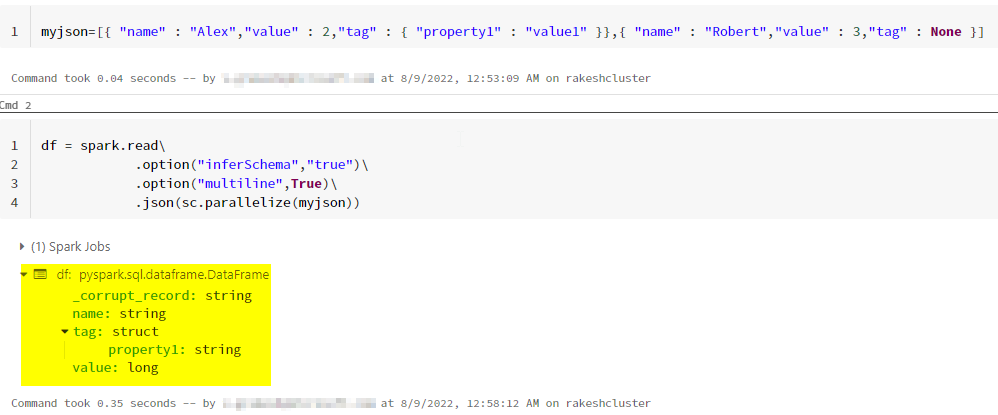
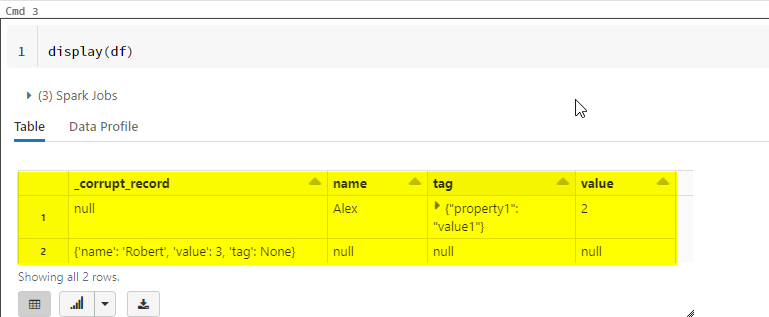
Here, in the above JSON, the None value in not inside any quotes and it may cause the corrupt_record as it is not any type of int, string etc.
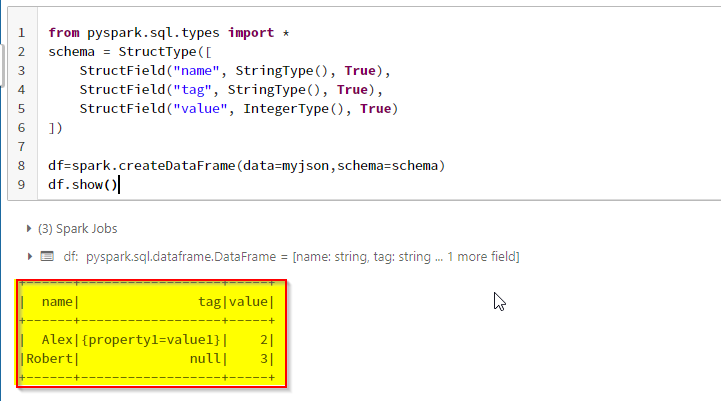
To get the desired dataframe like above, try to provide the schema of the JSON explicitly as suggested by @Alex Ott.
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType(), True),
StructField("tag", StringType(), True),
StructField("value", IntegerType(), True)
])
df=spark.createDataFrame(data=myjson,schema=schema)
df.show()
If we give the schema explicitly, spark identifies the type before and assigns null values for None.
OUTPUT:
If your JSON is a file, you can try like this SO thread by blackbishop.