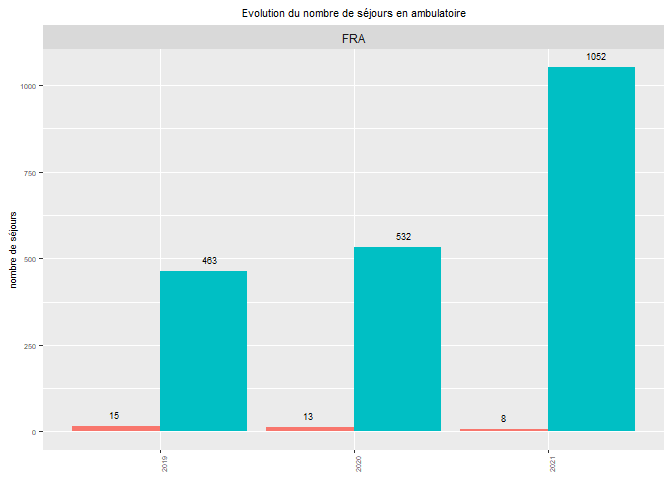
I am having trouble plotting using geom_text to put the values of the totals on top of my bar chart, as it puts every value on it (the value the variable takes for each "specialite") here is the bar plot i get. I would like to plot only the total of each bar, a little above each bar (the bars do not all have the same height so the labels should not all be at the same height too).
{kind=link}
Here is my current code :
NCN_1 %>%
filter(type_de_sejour == "Ambulatoires") %>%
pivot_longer(cols = c("nb_sejours_N","nb_sejours_N1","nb_sejours_N2"), values_to =
"visit") %>%
ggplot(aes(fill=name, y=visit, x=name))
geom_bar(position="stack", stat="identity", show.legend = FALSE)
facet_wrap(~site)
ggtitle("Evolution du nombre de séjours en ambulatoire")
theme(plot.title = element_text(hjust = 0.5, vjust = 1, size = 8),
axis.text.x = element_text(angle = 90, hjust = 0.5, size = 5),
legend.title = NULL,
axis.text.y = element_text(size = 5),
axis.title.y = element_text(size = 7))
labs(x = NULL,
y= "nombre de séjours",
fill = NULL)
geom_text(aes(x = name, y = as.numeric(visit), label = format(visit, digits = 1)),
size = 2.5,
position = position_dodge(.9),
inherit.aes = TRUE,
na.rm = TRUE)
scale_x_discrete(labels=c("nb_sejours_N2" = "2019", "nb_sejours_N1" = "2020",
"nb_sejours_N" = "2021"),
limits=c("nb_sejours_N2","nb_sejours_N1","nb_sejours_N"))
Here is the structure of my dataset, for reproducibility :
structure(list(type_de_sejour = c("Ambulatoires", "Hospitalisé",
"Hospitalisé", "Ambulatoires", "Hospitalisé", "Séances"),
specialite = c("ANESTHESIE REANIMATION", "ANESTHESIE REANIMATION",
"Autres", "CARDIO VASCULAIRE", "CARDIO VASCULAIRE", "CARDIO VASCULAIRE"
), CA_annee_N = c(2712L, 122180L, 0L, 822615L, 6905494L,
0L), nb_sejours_N = c(8L, 32L, 0L, 1052L, 2776L, 0L), nb_praticiens_N = c(5L,
8L, 0L, 12L, 15L, 0L), CA_annee_N1 = c(4231L, 78858L, 6587L,
327441L, 6413083L, 0L), nb_sejours_N1 = c(13L, 29L, 2L, 532L,
2819L, 0L), nb_praticiens_N1 = c(6L, 9L, 1L, 12L, 12L, 0L
), CA_annee_N2 = c(4551L, 27432L, 0L, 208326L, 7465440L,
575L), nb_sejours_N2 = c(15L, 8L, 0L, 463L, 3393L, 1L), nb_praticiens_N2 = c(6L,
4L, 0L, 11L, 13L, 1L), site = c("FRA", "FRA", "FRA", "FRA",
"FRA", "FRA"), activite_en_volume_N = c(8L, 32L, 0L, 1052L,
2776L, 0L), activite_en_volume_N1 = c(13L, 29L, 2L, 532L,
2819L, 0L), activite_en_volume_N2 = c(15L, 8L, 0L, 463L,
3393L, 1L), proportion_N = c(0.00059475131960449, 0.00237900527841796,
0, 0.0782097985279905, 0.206378707902758, 0), proportion_N1 = c(0.00107794361525705,
0.00240464344941957, 0.000165837479270315, 0.0441127694859038,
0.233747927031509, 0), proportion_N2 = c(0.000977517106549365,
0.000521342456826328, 0, 0.0301726946888237, 0.221114369501466,
6.5167807103291e-05)), class = c("grouped_df", "tbl_df",
"tbl", "data.frame"), row.names = c(NA, -6L), groups = structure(list(
site = "FRA", .rows = structure(list(1:6), ptype = integer(0), class =
c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -1L), .drop = TRUE))
[EDIT] : after receiving 2 answers, I tried this code :
NCN_1 %>%
filter(type_de_sejour == "Ambulatoires") %>%
pivot_longer(cols =
c("nb_sejours_N","nb_sejours_N1","nb_sejours_N2"), values_to =
"visit") %>%
group_by(name) %>%
mutate(total = sum(visit)) %>%
ggplot(aes(fill=name, y=visit, x=name))
geom_bar(stat="identity", show.legend = FALSE)
facet_wrap(~site)
ggtitle("Evolution du nombre de séjours en ambulatoire")
theme(plot.title = element_text(hjust = 0.5, vjust = 1, size =
8),
axis.text.x = element_text(angle = 90, hjust = 0.5, size =
5),
legend.title = NULL,
axis.text.y = element_text(size = 5),
axis.title.y = element_text(size = 7))
labs(x = NULL,
y= "nombre de séjours",
fill = NULL)
geom_text(aes(x = name, y = as.numeric(total), label =
format(total, digits = 1)),
size = 2.5,
position = position_dodge(1),
inherit.aes = TRUE,
na.rm = TRUE, vjust = 1)
scale_x_discrete(labels=c("nb_sejours_N2" = "2019",
"nb_sejours_N1" = "2020",
"nb_sejours_N" = "2021"),
limits=c("nb_sejours_N2","nb_sejours_N1","nb_sejours_N"))
But the problem is, as I facet, the bars on one facet being lower than the bars on the other, the labels are adapted to one facet and not the other. How could I solve this problem ?
{kind=link}
[EDIT 2] : Here is a better dataset to reproduce my example :
structure(list(type_de_sejour = c("Ambulatoires", "Hospitalisé",
"Hospitalisé", "Ambulatoires", "Hospitalisé", "Séances",
"Ambulatoires",
"Hospitalisé", "Ambulatoires", "Externes", "Hospitalisé",
"Ambulatoires",
"Hospitalisé"), specialite = c("ANESTHESIE REANIMATION",
"ANESTHESIE REANIMATION",
"Autres", "CARDIO VASCULAIRE", "CARDIO VASCULAIRE", "CARDIO
VASCULAIRE",
"CHIRUGIE CARDIAQUE", "CHIRUGIE CARDIAQUE", "ANESTHESIE
REANIMATION",
"ANESTHESIE REANIMATION", "ANESTHESIE REANIMATION", "Autres",
"Autres"), CA_annee_N = c(2712L, 122180L, 0L, 822615L, 6905494L,
0L, 78064L, 2483804L, 64310L, 0L, 265255L, 25298L, 3061L),
nb_sejours_N = c(8L,
32L, 0L, 1052L, 2776L, 0L, 129L, 388L, 171L, 0L, 280L, 34L, 3L
), nb_praticiens_N = c(5L, 8L, 0L, 12L, 15L, 0L, 2L, 2L, 10L,
0L, 12L, 3L, 3L), CA_annee_N1 = c(4231L, 78858L, 6587L, 327441L,
6413083L, 0L, 96453L, 3527754L, 50135L, 0L, 65145L, 454L, 4076L
), nb_sejours_N1 = c(13L, 29L, 2L, 532L, 2819L, 0L, 158L, 570L,
150L, 1L, 41L, 1L, 4L), nb_praticiens_N1 = c(6L, 9L, 1L, 12L,
12L, 0L, 3L, 3L, 11L, 1L, 8L, 1L, 3L), CA_annee_N2 = c(4551L,
27432L, 0L, 208326L, 7465440L, 575L, 135733L, 4745148L, 48583L,
0L, 33388L, 453L, 507L), nb_sejours_N2 = c(15L, 8L, 0L, 463L,
3393L, 1L, 236L, 835L, 154L, 3L, 26L, 1L, 1L), nb_praticiens_N2 =
c(6L,
4L, 0L, 11L, 13L, 1L, 3L, 3L, 11L, 1L, 5L, 1L, 1L), site = c("FRA",
"FRA", "FRA", "FRA", "FRA", "FRA", "FRA", "FRA", "PGS", "PGS",
"PGS", "PGS", "PGS"), activite_en_volume_N = c(8L, 32L, 0L, 1052L,
2776L, 0L, 129L, 388L, 171L, 0L, 280L, 34L, 3L),
activite_en_volume_N1 = c(13L,
29L, 2L, 532L, 2819L, 0L, 158L, 570L, 150L, 1L, 41L, 1L, 4L),
activite_en_volume_N2 = c(15L, 8L, 0L, 463L, 3393L, 1L, 236L,
835L, 154L, 3L, 26L, 1L, 1L), proportion_N =
c(0.00059475131960449,
0.00237900527841796, 0, 0.0782097985279905, 0.206378707902758,
0, 0.00959036502862241, 0.0288454390008178,
0.00589147286821705,
0, 0.00964685615848406, 0.00117140396210164,
0.000103359173126615
), proportion_N1 = c(0.00107794361525705, 0.00240464344941957,
0.000165837479270315, 0.0441127694859038, 0.233747927031509,
0, 0.0131011608623549, 0.0472636815920398, 0.00571689915389892,
3.81126610259928e-05, 0.00156261910206571, 3.81126610259928e-
05,
0.000152450644103971), proportion_N2 = c(0.000977517106549365,
0.000521342456826328, 0, 0.0301726946888237, 0.221114369501466,
6.5167807103291e-05, 0.0153796024763767, 0.054415118931248,
0.00479153702551338, 9.33416303671438e-05,
0.000808960796515246,
3.11138767890479e-05, 3.11138767890479e-05)), class =
c("grouped_df",
"tbl_df", "tbl", "data.frame"), row.names = c(NA, -13L), groups =
structure(list(
site = c("FRA", "PGS"), .rows = structure(list(1:8, 9:13),
ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), row.names = c(NA, -2L), class =
c("tbl_df",
"tbl", "data.frame"), .drop = TRUE))
CodePudding user response:
You could add a column per group with the sum of your visit column and use that as your label. With vjust you can adjust the position of the label like this:
library(ggplot2)
library(dplyr)
library(tidyr)
NCN_1 %>%
filter(type_de_sejour == "Ambulatoires") %>%
pivot_longer(cols = c("nb_sejours_N","nb_sejours_N1","nb_sejours_N2"), values_to =
"visit") %>%
group_by(name) %>%
mutate(total = sum(visit)) %>%
ggplot(aes(fill=name, y=visit, x=name))
geom_bar(stat="identity", show.legend = FALSE)
facet_wrap(~site)
ggtitle("Evolution du nombre de séjours en ambulatoire")
theme(plot.title = element_text(hjust = 0.5, vjust = 1, size = 8),
axis.text.x = element_text(angle = 90, hjust = 0.5, size = 5),
legend.title = NULL,
axis.text.y = element_text(size = 5),
axis.title.y = element_text(size = 7))
labs(x = NULL,
y= "nombre de séjours",
fill = NULL)
geom_text(aes(x = name, y = as.numeric(total), label = format(total, digits = 1)),
size = 2.5,
position = position_dodge(.9),
inherit.aes = TRUE,
na.rm = TRUE, vjust = -1)
scale_x_discrete(labels=c("nb_sejours_N2" = "2019", "nb_sejours_N1" = "2020",
"nb_sejours_N" = "2021"),
limits=c("nb_sejours_N2","nb_sejours_N1","nb_sejours_N"))
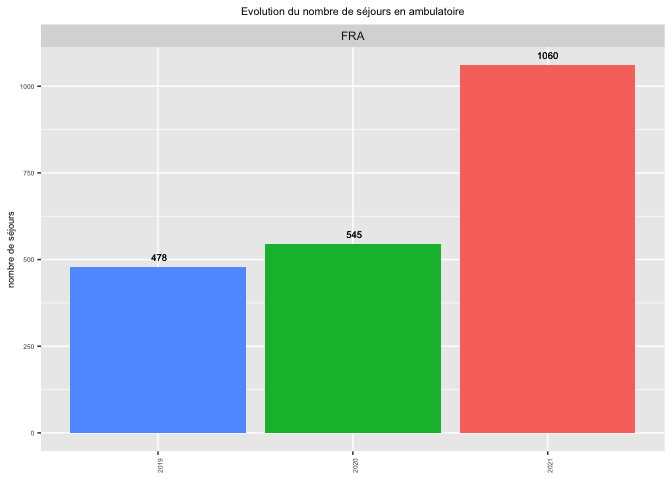
Created on 2022-08-10 by the reprex package (v2.0.1)
CodePudding user response:
The placement of the labels with respect to the bars can be achieved with vjust.
However, the main issue is that you have two rows in your data.frame for each combination of the x and y variables. This means that ggplot is essentially plotting two objects directly on top of each other. This is why you see two numbers per column in your figure.
You note that you actually want to distingush between each "specialite," but this variable doesn't actually appear in your ggplot() call. You can fix this problem by explicitly adding an aesthetic for "specialite" so that there is only one row per aesthetic combination.
Doing this with a stacked bar chart looks pretty horrible since the y-axis values in one group greatly exceeds that of the other. Accordingly, you can dodge the bars to place them side-by-side. This also will fix the labeling issue.
To demonstrate all of this, let's use a simplified example of your plot with your data:
# Packages
library(tidyr)
library(dplyr
library(ggplot2)
# Pre-process your data using your code
NCN_1 <- NCN_1 %>%
filter(type_de_sejour == "Ambulatoires") %>%
pivot_longer(
cols = c("nb_sejours_N", "nb_sejours_N1", "nb_sejours_N2"),
values_to =
"visit"
)
# Create a simpler figure that reproduces the problem
NCN_1 %>%
ggplot(aes(x = name, y = visit, label = visit))
geom_bar(stat = "identity")
geom_text()
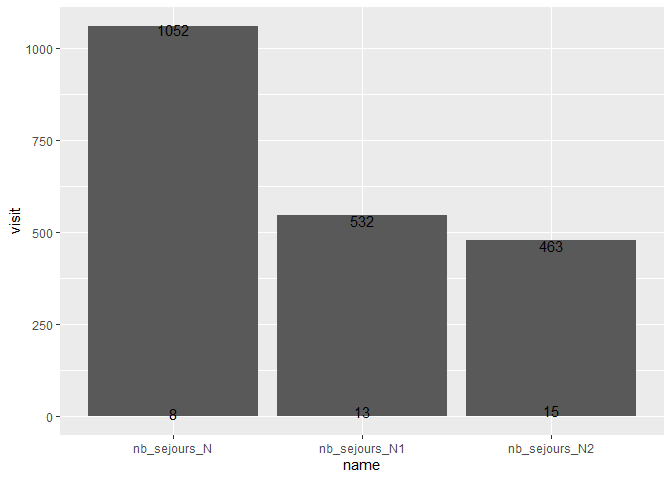
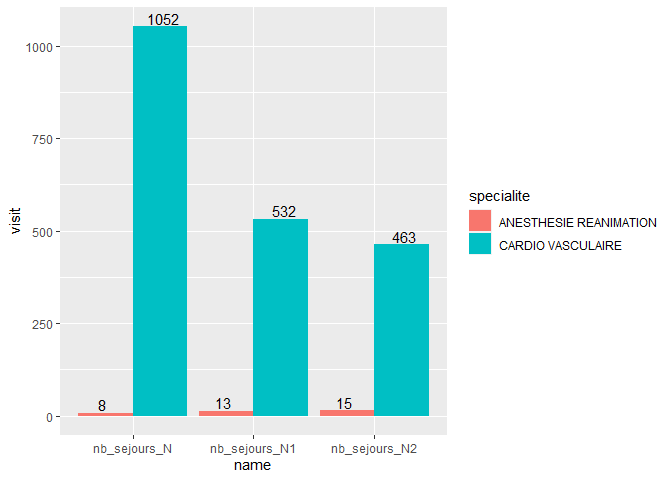
Let's now put the labels at the end and use separate bars for each specialite:
# Putting the bars side-by-side
NCN_1 %>%
ggplot(aes(x = name, y = visit, label = visit, fill = specialite))
geom_bar(stat = "identity", position = "dodge")
geom_text(position = position_dodge(width = 1), vjust = -0.2)
We could continue to stack the bars like you did, but as you can see in the bwlo, stacking the bars doesn't look very good:
NCN_1 %>%
ggplot(aes(x = name, y = visit, label = visit, fill = specialite))
geom_bar(stat = "identity")
geom_text(vjust = -0.7)
Now that I've shown this, let's apply the logic in the side-by-side plot to your figure while adjusting the location of the labels:
NCN_1 %>%
ggplot(aes(fill=specialite, y=visit, x=name))
geom_bar(position="dodge", stat="identity", show.legend = FALSE)
facet_wrap(~site)
ggtitle("Evolution du nombre de séjours en ambulatoire")
theme(plot.title = element_text(hjust = 0.5, vjust = 1, size = 8),
axis.text.x = element_text(angle = 90, hjust = 0.5, size = 5),
legend.title = NULL,
axis.text.y = element_text(size = 5),
axis.title.y = element_text(size = 7))
labs(x = NULL,
y= "nombre de séjours",
fill = NULL)
geom_text(aes(x = name, y = as.numeric(visit), label = format(visit, digits = 1)),
size = 2.5,
position = position_dodge(1),
vjust = -1,
inherit.aes = TRUE,
na.rm = TRUE)
scale_x_discrete(labels=c("nb_sejours_N2" = "2019", "nb_sejours_N1" = "2020",
"nb_sejours_N" = "2021"),
limits=c("nb_sejours_N2","nb_sejours_N1","nb_sejours_N"))