I've seen the use of fragment quite frequently within a Lexing rule, but not quite sure what its use is, or why it cannot just be removed. For example in the following rule:
NUMBER
: DECIMAL ([Ee] [ -]?[0-9] )?
;
fragment DECIMAL
: [0-9] ('.' [0-9]*)? | '.' [0-9]
;
When I remove the fragment I still get the same parse tree. So what exactly is the use of using fragment or is it mainly an annotative type of thing?
As another example from this 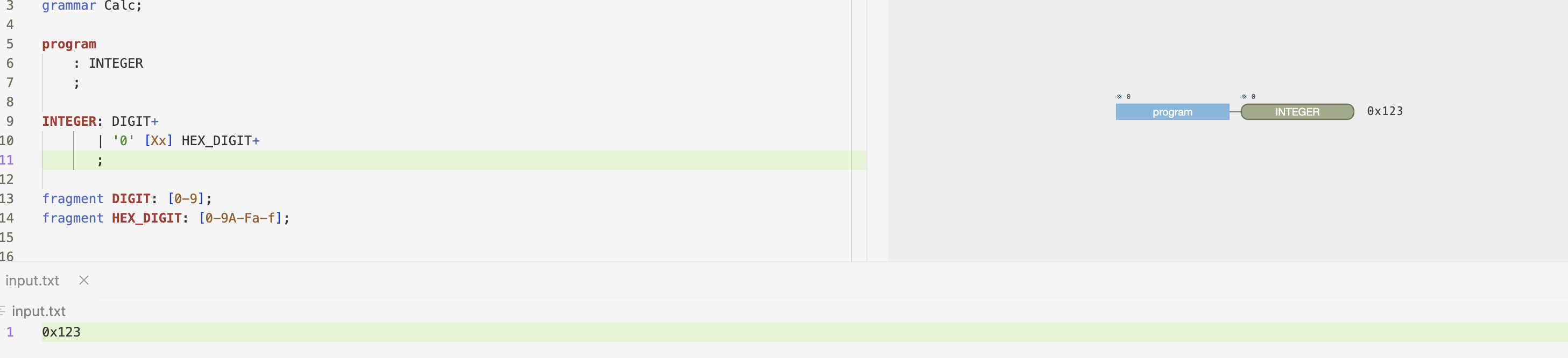
And without fragments:
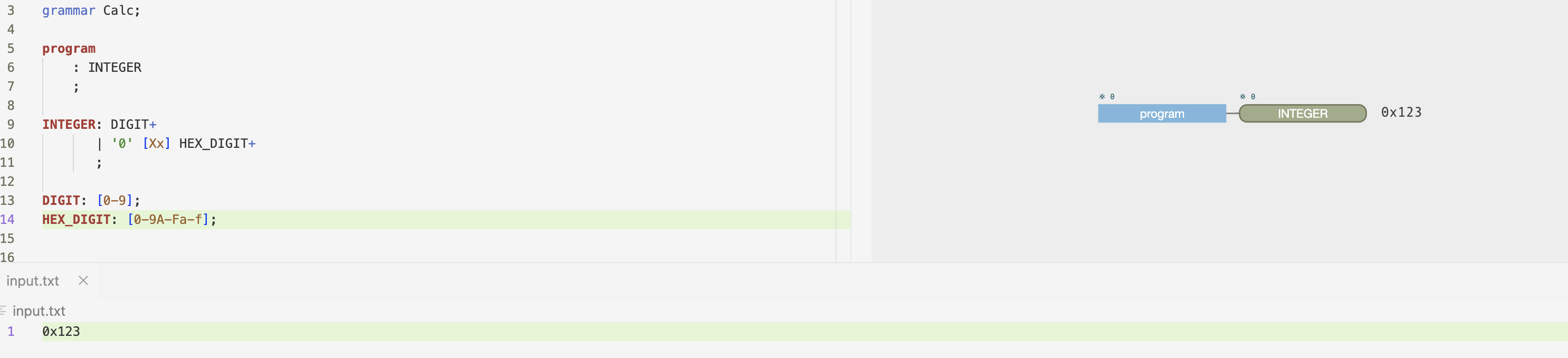
Could someone please explain why these would be useful then?
CodePudding user response:
The fragment declaration prevents the part from being recognized as a token. That might not be necessary very often, but it can definitely save you from hard-to-find bugs.
Let's take the second example in your post, without the fragment modifiers:
expression: INTEGER ;
INTEGER: DIGIT
| '0' [Xx] HEX_DIGIT
;
DIGIT: [0-9];
HEX_DIGIT: [0-9A-Fa-f];
Now, we decide that we want to add variables to the grammar:
expression: INTEGER | IDENTIFIER ;
INTEGER: DIGIT
| '0' [Xx] HEX_DIGIT
;
DIGIT: [0-9];
HEX_DIGIT: [0-9A-Fa-f];
IDENTIFIER: LETTER (LETTER | DIGIT) ;
LETTER: [A-Za-z] ;
Do you see the bug?
The parser won't handle the input a, although it has no trouble with ax or i. That's because the tokeniser will interpret a as a HEX_DIGIT, not an IDENTIFIER.
Of course, I could have prevented that by putting HEX_DIGIT after IDENTIFIER, but that's more thinking about lexer rule ordering than I really want to do. I'd like the implementation details of IDENTIFIER and INTEGER to not interfere with each other, thank you very much.
Correctly flagging non-token fragments, like LETTER, DIGIT and HEX_DIGIT saves me from having to think about whether a fragment might somehow manage to high-jack a token definition somewhere else in the file.
Here's a possibly more pernicious example, based on your first example:
NUMBER : DECIMAL EXPONENT? ;
EXPONENT: [Ee] [ -]? [0-9] ;
DECIMAL : [0-9] ('.' [0-9]*)? | '.' [0-9] ;
Once I add expressions to that grammar, I'll find that f 17 is fine, but e 17 is a syntax error. Why? Because it is recognised as an EXPONENT, rather than being parsed as an expression. No reordering of lexical rules will prevent that. But adding the fragment modifiers does the trick.