Sometimes I get a bit confused between a lexing rule vs. a parsing rule, and there's been a nice thread on it 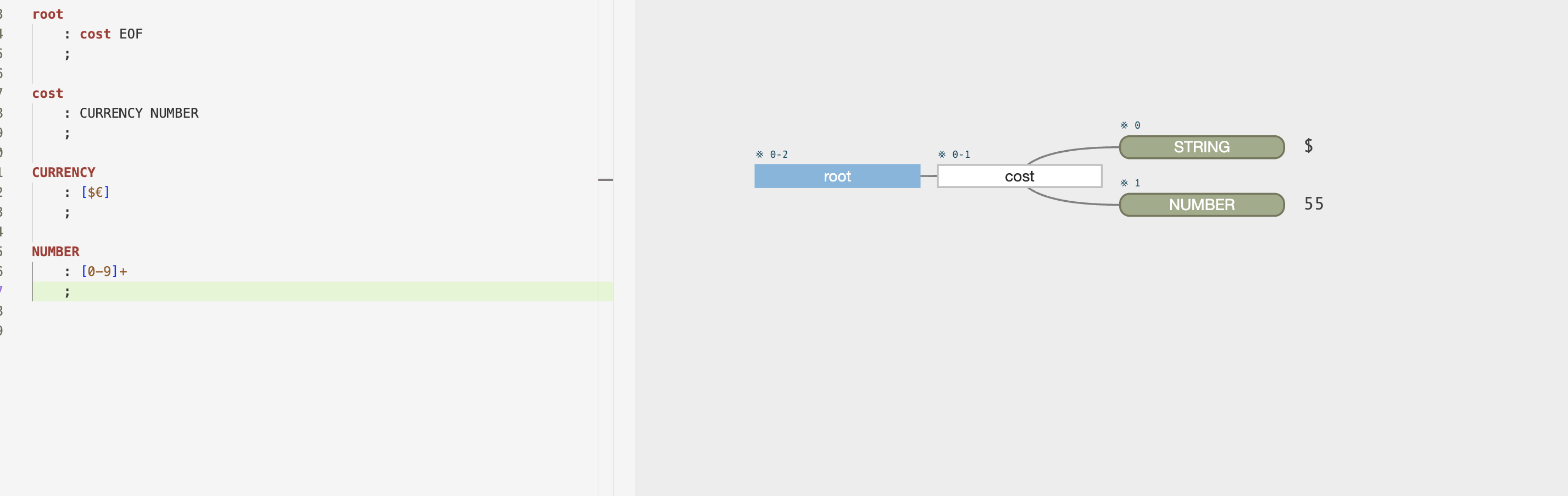
But if we set the cost as a lexing rule, it will not break it down any further:
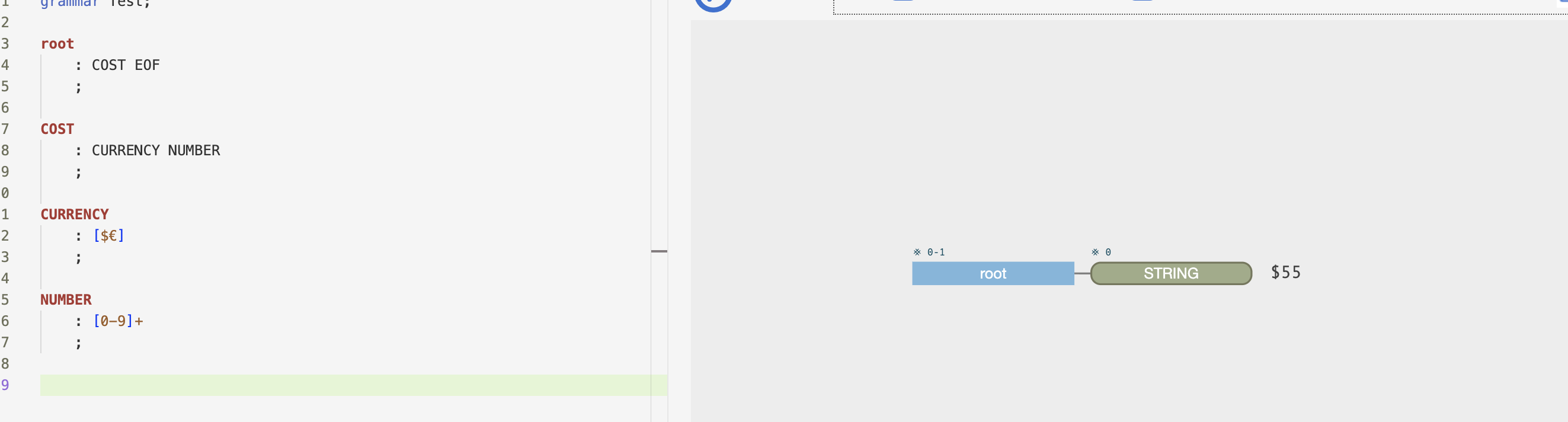
So basically a lexing rule is atomic and terminal, whereas a parsing rule is more like a molecule that consists of various parts (atoms) that can be seen within it. Is that a good description/understanding of it?
CodePudding user response:
Your "Update" is on the right track. That's a definite distinction.
You also need to understand the ANTLR pipeline. I.e. that the stream of characters is processed by the Lexer rules to produce a stream of tokens (atoms, in you analogy). It does not do that with recursive descent rule matching, but rather attempts to match you input against all of the Lexer rules. Where:
- The rule that matches the longest sequence of input characters will "win"
- In the event that multiple Lexer rules match the same length character sequence, then the rule that occurs first will "win"
Once you've got you stream of "atoms" (aka Tokens), then ANTLR uses the parser rules (recursively from the start rule) to try to match sequences of tokens.