I have two dataframes.
DF1
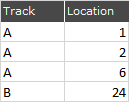
DF2
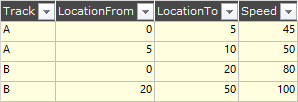
I want to add a column to DF1, 'Speed', that references the track category, and the LocationFrom and LocationTo range, to result in the below.
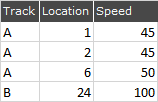
I have looked at merge_asof, and IntervalIndex, but unable to figure out how to reference the category before the range.
Thanks.
CodePudding user response:
Check Below code: SQLITE
import pandas as pd
import sqlite3
conn = sqlite3.connect(':memory:')
DF1.to_sql('DF1', con = conn, index = False)
DF2.to_sql('DF2', con = conn, index = False)
pd.read_sql("""Select DF1.*, DF2.Speed
From DF1
join DF2 on DF1.Track = Df2.Track
AND DF1.Location BETWEEN DF2.LocationFrom and DF2.LocationTo""", con=conn)
Output:
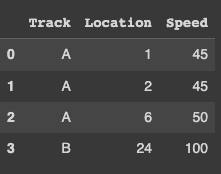
CodePudding user response:
It works, but I would like to see someone do this without a for loop and without creating mini dataframes.
import pandas as pd
data1 = {'Track': list('AAAB'), 'Location': [1, 2, 6, 24]}
df1 = pd.DataFrame(data1)
data2 = {'Track': list('AABB'), 'LocationFrom': [0, 5, 0, 20], 'LocationTo': [5, 10, 20, 50], 'Speed': [45, 50, 80, 100]}
df2 = pd.DataFrame(data2)
speeds = []
for k in range(len(df1)):
track = df1['Track'].iloc[k]
location = df1['Location'].iloc[k]
df1_track = df1.loc[df1['Track'] == track]
df2_track = df2.loc[df2['Track'] == track]
speeds.append(df2_track['Speed'].loc[(df2_track['LocationFrom'] <= location) & (location < df2_track['LocationTo'])].iloc[0])
df1['Speed'] = speeds
print(df1)
Output:
Track Location Speed
0 A 1 45
1 A 2 45
2 A 6 50
3 B 24 100
CodePudding user response:
This approach is probably not viable if your tables are large. It creates an intermediate table which has a merge of all pairs of matching Tracks between df1 and df2. Then it removes rows where the location is not between the boundaries. Thanks @Aeronatix for the dfs.
The all_merge intermediate table gets really big really fast. If a1 rows of df1 are Track A, a2 in df2 etc.. then the total rows in all_merge will be a1*a2 b1*b2 c1*c2... z1*z2 which might or might not be gigantic depending on your dataset
all_merge = df1.merge(df2)
results = all_merge[all_merge.Location.between(all_merge.LocationFrom,all_merge.LocationTo)]
print(results)