I have a dataframe that looks something like:
| matter | work_date |
|---|---|
| 1 | 01/01/2020 |
| 2 | 01/02/2020 |
| 1 | 01/04/2020 |
| 2 | 01/05/2020 |
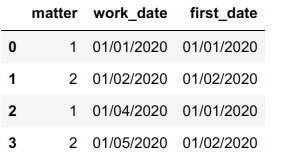
I want a new column which finds the minimum work_date of all rows with the same matter number so that I can do some time delta calculations. so the final result would look like this:
| matter | work_date | first_date |
|---|---|---|
| 1 | 01/01/2020 | 01/01/2020 |
| 2 | 01/02/2020 | 01/02/2020 |
| 1 | 01/04/2020 | 01/01/2020 |
| 2 | 01/05/2020 | 01/02/2020 |
Right now, I'm using the following code, but it is taking quite a while to run (the dataframe has approx 300k rows and I'm on an ancient computer).
min_dict = {}
def check_dict(val):
return min_dict.setdefault(val,min(df[df['tmatter']==val]['tworkdt']))
df['first_day'] = df.apply (lambda row: check_dict(row.tmatter), axis = 1)
Is there a better way to approach this?
CodePudding user response:
transform does what you want and should be fast
The steps are (1) group the rows together that have the same matter (2) for each group calculate the minimum work_date and (3) save these values as a new column.
import pandas as pd
import io
df = pd.read_csv(io.StringIO("""
matter work_date
1 01/01/2020
2 01/02/2020
1 01/04/2020
2 01/05/2020
"""), delim_whitespace=True)
df['first_date'] = df.groupby('matter')['work_date'].transform('min')
print(df)