I have a pandas dataframe (df) with columns A, B, C, and D. I have situation in which I wish to de-duplicate the values in the first two columns, one-hot-encode the third column, and do a one-hot-encoding of the last column in such a way that is references
Individual Columns
- Column
Acontains identifiers of objects of measurement. These are not currently unique to a row indf, but that is desired. - Column
Bcontains floats that are duplicated in each occurrence when values ofArepeats. These should be remain paired to - Column
Ccontains a categorical variable describing something about each objective of measure. - Column
Dis another categorical variable which describes a property of a given level ofC.
Subsets of Columns
- Every row of
dfis unique. - Not all pairs of values from columns
AandBare unique, which is due to mapping to distinct values fromC. - Every pair of values from columns
AandCare unique among the rows. - Not all pairs of values from columns
AandDare unique. - Not all pairs of values from columns
CandDare unique. - Every triple of values from columns
A,BandCare unique.
Example
The last point of about one-hot-encoding the D column requires explanation, which I will attempt in an example. The following data table is analogous to my problem.
| Cat_ID | Tail_Length | Part | Colour |
|---|---|---|---|
| 1 | 23.0 | nose | Brown |
| 1 | 23.0 | belly | white |
| 2 | 22.5 | nose | pink |
| 2 | 22.5 | belly | black |
| 2 | 22.5 | tail | black |
| 3 | 20.0 | tail | orange |
Our first column identifies the cat. I would like there to be one row per cat. The second column gives the length of the cat's tail, which is directly tied to the cat. The tail length need not be unique to a cat, but each cat should have only one tail length. The Part is referring to some body part of the cat. I would like to one-hot the body parts, which I would normally do using pd.get_dummies. Since a cat having multiple body parts is allowed, i.e. not mutually exclusive, it makes sense to aggregate the multiple rows of one-hot encoded parts by summation to get a less sparse 1-0 row vector. The last column, Colour, refers to the colour of the given body part for the cat. I would also like Colour to be one-hot-encoded, but in a way that refers to which body part we are referring to.
Question
Given such a data frame loaded as a pandas data frame object called df, how can I achieve the de-duplication and the (sort of hierarchical) one-hot encoding?
CodePudding user response:
Is this the type of output you want?
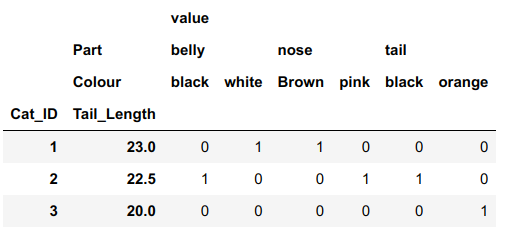
import pandas as pd
import io
df = pd.read_csv(io.StringIO(
"""Cat_ID Tail_Length Part Colour
1 23.0 nose Brown
1 23.0 belly white
2 22.5 nose pink
2 22.5 belly black
2 22.5 tail black
3 20.0 tail orange"""
),delim_whitespace=True)
onehot_df = df.assign(value=1).pivot_table(
index = ['Cat_ID','Tail_Length'],
columns = ['Part','Colour'],
fill_value = 0,
)
print(onehot_df)