I have two pandas dataframes, df1 and df2
df1 looks like this:
|Name |Age |Country |Industry|Score |
-------------------------------------------------
|BIMBOA MM |8 |CO |Paper |5 |
|AGUA* MM |13 |CH |Finance |7 |
|ENTEL CI |5 |PE |Paper |2 |
|AXTELCPO MM |4 |CO |Oil |1 |
|ALPEKA MM |2 |BR |Oil |9 |
|KIMBERA MM |12 |AR |Finance |1 |
And df2 looks like this:
|Name |Age |Country |Industry|Research Level |
-------------------------------------------------------------
|BIMBOA.MX |8 |CO |Paper |4 |
|AGUA.MX |13 |CH |Finance |0 |
|86964WAJ1=1M |5 |PE |Paper |2 |
|USP9810XAA9=1M |4 |CO |Oil |1 |
|KIMBERA.MX |2 |BR |Oil |0 |
|AXTELCPO.MX |12 |AR |Finance |3 |
And I want to merge them by the column "Name". But, I want to allow to merge with not exact coincidence of the strings in the column. So I coul get somethin like this:
|Name |Age |Country |Industry|Score |Research Level |
-----------------------------------------------------------------
|BIMBOA MM |8 |CO |Paper |5 |4 |
|AGUA* MM |13 |CH |Finance |7 |0 |
|ENTEL CI |5 |PE |Paper |2 |NaN |
|AXTELCPO MM |4 |CO |Oil |1 |3 |
|ALPEKA MM |2 |BR |Oil |9 |NaN |
|KIMBERA MM |12 |AR |Finance |1 |0 |
I tried with this:
merged_df1_df2 = pd.merge_asof(df1, df2, on='Name')
But I got this error:
MergeError: Incompatible merge dtype, dtype('O') and dtype('O'), both sides must have numeric dtype
Do you guys any idea of how can I do this?
CodePudding user response:
Given the provided data, it looks like a simple merge on the cleaned-up Name columns should do the trick:
df1.merge(df2[['Research Level']], how='left',
left_on=df1['Name'].str.extract('(\w )', expand=False),
right_on=df2['Name'].str.extract('(\w )', expand=False),
).drop(columns='key_0')
output:
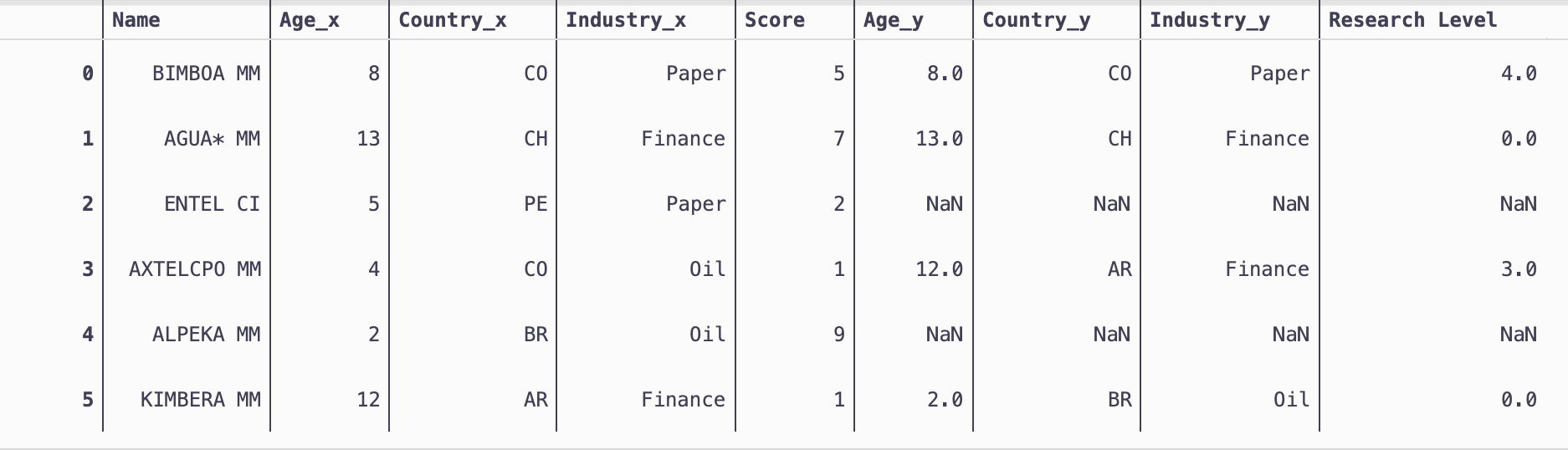
Name Age Country Industry Score Research Level
0 BIMBOA MM 8 CO Paper 5 4.0
1 AGUA* MM 13 CH Finance 7 0.0
2 ENTEL CI 5 PE Paper 2 NaN
3 AXTELCPO MM 4 CO Oil 1 3.0
4 ALPEKA MM 2 BR Oil 9 NaN
5 KIMBERA MM 12 AR Finance 1 0.0
CodePudding user response:
import pandas as pd
df1 = pd.DataFrame({'Name': ['BIMBOA MM', 'AGUA* MM', 'ENTEL CI', 'AXTELCPO MM', 'ALPEKA MM', 'KIMBERA MM'],
'Age': [8, 13, 5, 4, 2, 12],
'Country': ['CO','CH','PE','CO','BR','AR'],
'Industry': ['Paper','Finance','Paper','Oil','Oil','Finance'],
'Score': [5,7,2,1,9,1]
})
df2 = pd.DataFrame({'Name': ['BIMBOA MM', 'AGUA* MM', '86964WAJ1=1M', 'USP9810XAA9=1M', 'KIMBERA MM','AXTELCPO MM'],
'Age': [8, 13, 5, 4, 2, 12],
'Country': ['CO','CH','PE','CO','BR','AR'],
'Industry': ['Paper','Finance','Paper','Oil','Oil','Finance'],
'Research_Level': [4,0,2,1,0,3]
})
df_left_merge = pd.merge(df1, df2, how='left')
print(df_left_merge)
CodePudding user response:
Use difflib, but got to find the cutoff value that meets your request.
import difflib
def get_closest_match(x, other, cutoff):
matches = difflib.get_close_matches(x, other, cutoff=cutoff)
return matches[0] if matches else None
def fuzzy_merge(df1, df2, left_on, right_on, how='inner', cutoff=0.6):
df_other= df2.copy()
df_other[left_on] = [get_closest_match(x, df1[left_on], cutoff)
for x in df_other[right_on]]
return df1.merge(df_other, on=left_on, how=how)
fuzzy_merge(df1, df2, 'Name', 'Name', how='left', cutoff=0.5)
Reference: is it possible to do fuzzy match merge with python pandas?
CodePudding user response:
To merge string columns without exact match you need to perform fuzzy merge
You can check different versions of this merge on this question: is it possible to do fuzzy match merge with python pandas?