I am looking to annotate a histogram with some text always in the top right corner. I've been working from similar questions, but my text is always getting cutoff so I just get the first few letters annotated in the plot.
How can I annotate text to the top right of a histogram regardless of the data? I would rather not set x and y based of values per plot as I am making the same plot and annotation for different distributions of multiple columns.
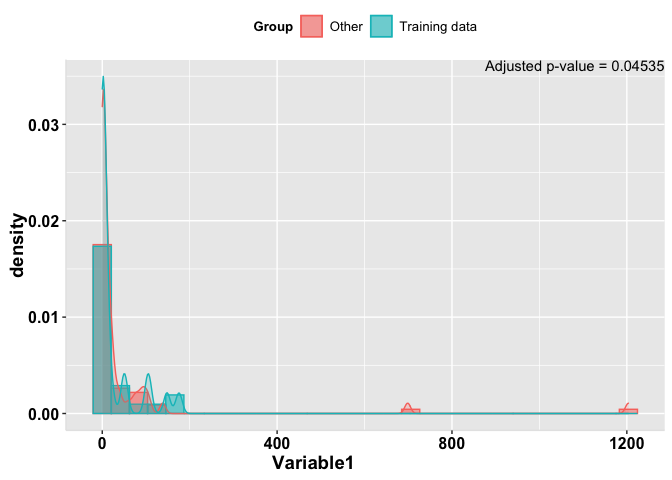
An example of one of the plots with 1 column that I'm trying is this:
library(easyGgplot2)
library(ggpubr)
library(data.table)
library(dplyr)
library(tidyverse)
library(ggplot2)
ggplot2.histogram(data=df, xName='Variable1',
groupName='Group', legendPosition="top",
alpha=0.5, addDensity=TRUE,
) annotate("text", label= "Adjusted p-value = 0.04535",
x = Inf, y = Inf)
Running this plot with my example data below will give the plot with the cutoff text that I am getting.
Example data:
df <- structure(list(Variable1 = c(3.75013, 0.706029, 107.02, 23.1238,
93.5506, 12.1977, 0.0213773, 0.226452, 58.5638, 0.230506, 2.0151,
15.8432, 0.507668, 0.206429, 0.0500646, 8.05844, 99.9986, 42.7651,
NA, NA, 0, NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, NA, 21.7922,
4.33389, 17.6949, 698.604, 0.0783803, 0.254815, 2.27979, 3.80408,
0.169416, 6.26137, 20.1664, 3.28596, 6.48836, 10.49, 1203.58,
5.31567, 87.9661, 79.1385, 10.8811, 71.5266, 19.8119, 0.929706,
1.97972, 36.3889, NA, NA, NA, NA, NA, NA, NA, NA, 29.6171, 14.0895,
0.438421, 3.61988, 2.89518, 0.606338, 138.414, 0.0567656, 0.452469,
14.9471, 0.814494, 9.64228, 9.53371, 107.082, 21.0549, 52.4131,
48.7998, 5.05289, 6.96671, 148.091, 3.00863, 0.549199, 0.031401,
0.0286301, 0.137585, 0, 8.88295, 1.2546, 0.372526, 0.102492,
175.478, 103.448, 0.157544, 2.81689, 0.203345, 0.369321), Group = c("Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Other", "Other", "Other",
"Other", "Other", "Other", "Other", "Training data", "Training data",
"Training data", "Training data", "Training data", "Training data",
"Training data", "Training data", "Training data", "Training data",
"Training data", "Training data", "Training data", "Training data",
"Training data", "Training data", "Training data", "Training data",
"Training data", "Training data", "Training data", "Training data",
"Training data", "Training data", "Training data")), row.names = c(NA,
-100L), class = c("data.table", "data.frame"))
CodePudding user response:
You could use hjust and vjust of 1 in your annotate call like this:
library(easyGgplot2)
ggplot2.histogram(data=df, xName='Variable1',
groupName='Group', legendPosition="top",
alpha=0.5, addDensity=TRUE,
) annotate("text", label= "Adjusted p-value = 0.04535",
x = Inf, y = Inf, hjust = 1, vjust = 1)
Created on 2022-08-13 by the reprex package (v2.0.1)