I am still quite new to Python and have a problem creating the code for following problem. I have a dataframe with many columns that look like this:
Some of the rows have all the regions, others only have 1 or 3, each row has unique values.
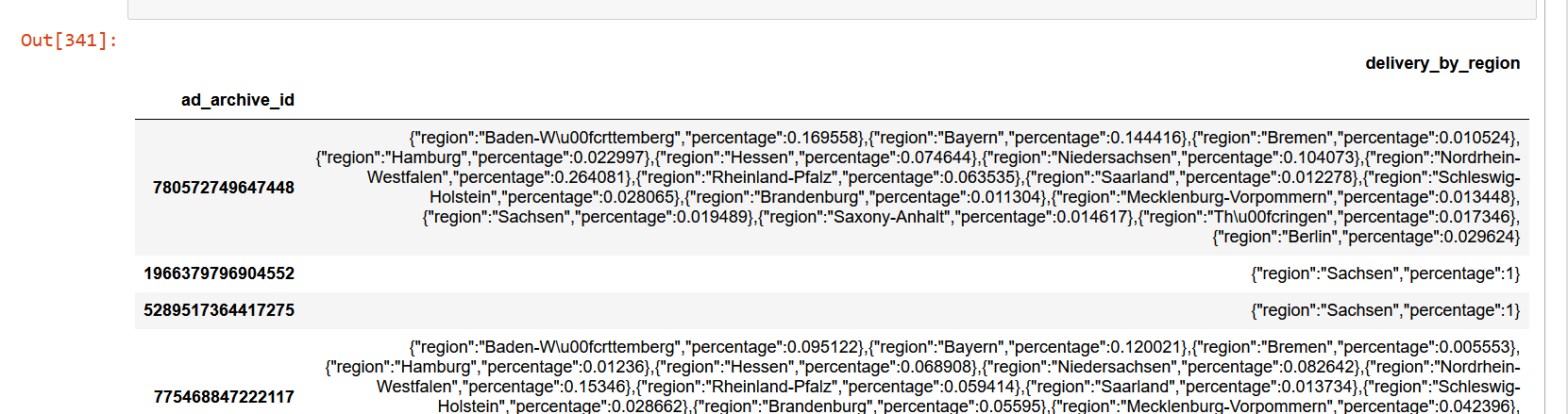
This is an example for a cell content:
{"region":"Baden-W\u00fcrttemberg","percentage":0.169558},{"region":"Bayern","percentage":0.144416},{"region":"Bremen","percentage":0.010524},{"region":"Hamburg","percentage":0.022997},{"region":"Hessen","percentage":0.074644},{"region":"Niedersachsen","percentage":0.104073},{"region":"Nordrhein-Westfalen","percentage":0.264081},{"region":"Rheinland-Pfalz","percentage":0.063535},{"region":"Saarland","percentage":0.012278},{"region":"Schleswig-Holstein","percentage":0.028065},{"region":"Brandenburg","percentage":0.011304},{"region":"Mecklenburg-Vorpommern","percentage":0.013448},{"region":"Sachsen","percentage":0.019489},{"region":"Saxony-Anhalt","percentage":0.014617},{"region":"Th\u00fcringen","percentage":0.017346},{"region":"Berlin","percentage":0.029624}
I need to create a df where each region is its own column and the row is the corresponding percentage. Tried with following code to get the columns out, where column looks as follows:
import itertools as itts
lysts = [t[1] for t in column.iteritems()]
regions = set(itts.chain.from_iterable([[d["region"] for d in lyst] for lyst in lysts]))
print(regions)
Unfortunately I always get TypeError: string indices must be integers, and after checking it looks like its not recognizing the values as dictionaries but as a pandas Series/List.
Ultimately I want to have a df where each column is a region and the rows are their corresponding percentages. Something like this e.g.
CodePudding user response:
Is this how your desired output should look like for one row?
df = pd.DataFrame([item['percentage'] for item in region_list]).T
df.columns = [item['region'] for item in region_list]
>>>
Baden-Württemberg Bayern Bremen Hamburg Hessen Niedersachsen NordrheinWestfalen Rheinland-Pfalz Saarland Schleswig-Holstein Brandenburg Mecklenburg-Vorpommern Sachsen Saxony-Anhalt Thüringen Berlin
0 0.169558 0.144416 0.010524 0.022997 0.074644 0.104073 0.264081 0.063535 0.012278 0.028065 0.011304 0.013448 0.019489 0.014617 0.017346 0.029624
CodePudding user response:
It looks like your data is probably all string type (if it were a list or array it would be enclosed in brackets), which means you'll need to parse it somehow. This is what the error is telling you - I can reproduce TypeError: string indices must be integers with this line:
In [4]: sample = '{"region":"Baden-W\u00fcrttemberg","percentage":0.169558},{"region":"Bayern","percentage":0.144416},{
...: "region":"Bremen","percentage":0.010524},{"region":"Hamburg","percentage":0.022997},{"region":"Hessen","percent
...: age":0.074644},{"region":"Niedersachsen","percentage":0.104073},{"region":"Nordrhein-Westfalen","percentage":0.
...: 264081},{"region":"Rheinland-Pfalz","percentage":0.063535},{"region":"Saarland","percentage":0.012278},{"region
...: ":"Schleswig-Holstein","percentage":0.028065},{"region":"Brandenburg","percentage":0.011304},{"region":"Mecklen
...: burg-Vorpommern","percentage":0.013448},{"region":"Sachsen","percentage":0.019489},{"region":"Saxony-Anhalt","p
...: ercentage":0.014617},{"region":"Th\u00fcringen","percentage":0.017346},{"region":"Berlin","percentage":0.029624
...: }'
In [5]: sample["region"]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [5], in <cell line: 1>()
----> 1 sample["region"]
TypeError: string indices must be integers
So, you'll need to parse the string data in each cell with json.loads, ast.literal_eval, or pd.read_json. I'll use the last option just because it will return a dataframe, which we can easily manipulate into the format we need. But just be warned that this will be a slow operation if you have a lot of data.
Something along these lines should do the trick though. You can walk through the applied operation using sample instead of data to understand what is happening at each step:
# apply on a Series/DataFrame column will run the applied function on each cell
parsed = df.delivery_by_region.apply(
# in each cell:
lambda data: (
# read the cell as json. We'll put brackets around the
# string so it's valid json (you can't just have comma-separated dicts)
pd.read_json("[" data "]")
# move the region field into the index
.set_index("region")
# select the percentage column to return a Series. pandas will
# interpret a series in the result of an apply as the other dimension
# in the result, so we'll get a DataFrame back
.percentage
)
)
I made a dummy mock-up of your data with random-length subsets of the string you provided. Since it's the same string repeated over and over the values are all the same with the exception of the region list, but you get the idea:
df = pd.DataFrame(
[
("},{".join(sample[:-1].split("},{")[:np.random.randint(1, 16)]) "}")
for i in range(20)
],
columns=["delivery_by_region"],
)
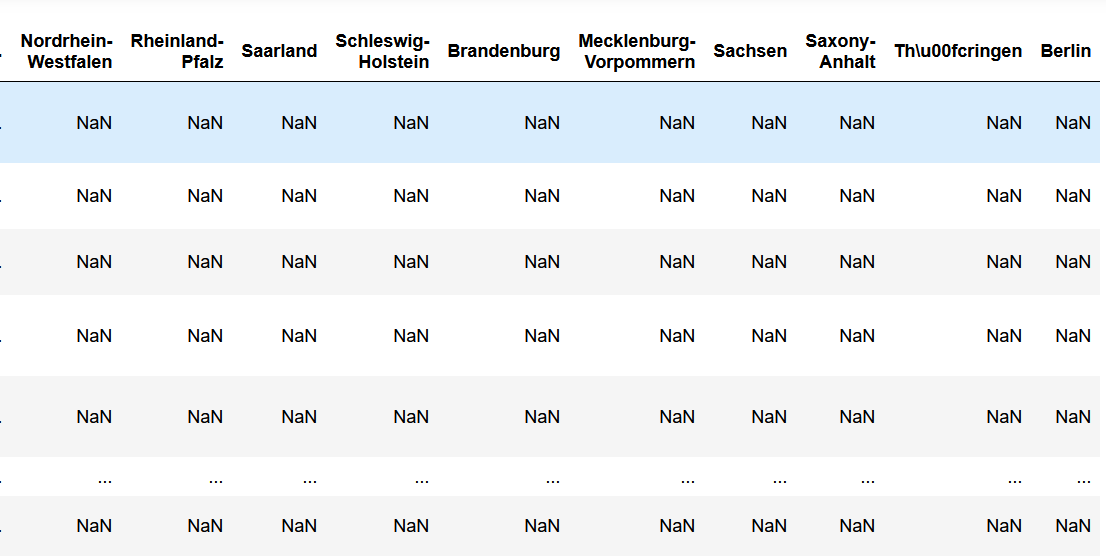
Running the above function on this results in the following DataFrame:
region Baden-Württemberg Bayern Bremen Hamburg ... Mecklenburg-Vorpommern Sachsen Saxony-Anhalt Thüringen
0 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
1 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
2 0.169558 0.144416 0.010524 0.022997 ... 0.013448 NaN NaN NaN
3 0.169558 0.144416 0.010524 0.022997 ... 0.013448 NaN NaN NaN
4 0.169558 0.144416 NaN NaN ... NaN NaN NaN NaN
5 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
6 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
7 0.169558 0.144416 0.010524 NaN ... NaN NaN NaN NaN
8 0.169558 0.144416 0.010524 0.022997 ... 0.013448 0.019489 0.014617 NaN
9 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
10 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
11 0.169558 0.144416 NaN NaN ... NaN NaN NaN NaN
12 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
13 0.169558 0.144416 NaN NaN ... NaN NaN NaN NaN
14 0.169558 0.144416 0.010524 0.022997 ... 0.013448 0.019489 0.014617 0.017346
15 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
16 0.169558 0.144416 0.010524 0.022997 ... 0.013448 0.019489 NaN NaN
17 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
18 0.169558 0.144416 0.010524 0.022997 ... NaN NaN NaN NaN
19 0.169558 0.144416 NaN NaN ... NaN NaN NaN NaN
[20 rows x 15 columns]