I need to create a column that, if the first and last value in the column 'date_int' of each group (based on column ID) is 'yes', returns 'yes', otherwise it returns 'no' (which would be the output in column 'multi_index').
ID A index timestamp date_int multi_index
1 activity1 1 2021-02-01 12:03:20 yes no
1 activity2 2 2021-02-11 12:03:20 no
1 activity3 3 2021-11-23 11:46:40 no
1 activity4 4 2021-11-24 11:46:40 no
1 activity5 5 2021-11-25 11:46:40 no
1 activity6 6 2021-11-26 11:46:40 no
2 activity7 1 2021-03-01 12:03:20 yes yes
2 activity8 2 2021-03-11 12:03:20 no
2 activity9 3 2021-12-23 11:46:40 no
2 activity10 4 2021-12-27 11:46:40 no
2 activity11 5 2021-12-28 11:46:40 no
2 activity12 6 2021-12-29 11:46:40 yes
Any idea?
CodePudding user response:
Ambiguity: What do you mean by "last"? The highest index? Or the highest timestamp? I'll assume index.
Another issue: Did you want "no" or "" for multi? I'll assume "no".
I think this will generate the desired yes/no:
SELECT A,
IF(( SELECT ... ) = 'yes')
AND( SELECT ... ) = 'yes'),
'yes', 'no') AS multi
FROM ( SELECT A,
1 AS mini,
MAX(`index`) AS maxi
FROM tbl ) AS x
Where the first SELECT is
SELECT date_int
FROM tbl
WHERE tbl.A = x.A
AND tbl.index = mini
and the second is
SELECT date_int
FROM tbl
WHERE tbl.A = x.A
AND tbl.index = maxi
Before proceeding, run that combined query. See if it delivers the 'correct' stuff.
To actually add the column:
ALTER TABLE tbl ADD COLUMN multi VARCHAR(3) NULL;
Then top populate it:
UPDATE tbl AS a
JOIN ( ... ) AS b ON a.A = b.A
AND a.index = 1
SET a.multi = b.multi;
where the "..." is that mess I created above.
But.... Consider not including multi in the current table, since it is empty when index != 1. Instead, consider having another table with only one row per A. And a second column for multi. Then the UPDATE becomes an INSERT (with several changes).
CodePudding user response:
I couldn't do it succinctly but...
First, I created another dataframe with the results of the comparisons:
result = df.sort_values('index').groupby('ID', as_index=False).apply(lambda x: x.iloc[[0, -1]].date_int.apply(lambda x: x == 'yes').all())
result.columns = ['ID', 'check']
I used the index column to sort the dataframe and avoid unexpected results. You can change it to sort by the column that makes the most sense for you. I also renamed the columns of this auxiliar dataframe
Then, I created the desired result column:
df['multi_index'] = ''
And a function to change the value of the first row of each group to 'yes' or 'no' based on the result dateframe
def change_first_record(x):
x['multi_index'].iloc[0] = result[result.ID == x.ID.values[0]].check.apply(lambda x: 'yes' if x else 'no').values[0]
return x
Now, we just have to apply the above function to our original dataframe:
df = df.groupby('ID').apply(change_first_record)
Resulting in:
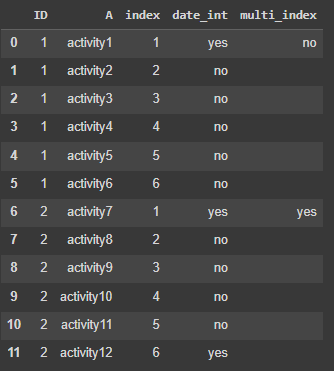
Hope it helps you find a cleaner way to do so!
CodePudding user response:
Here is a way using groupby() and transform()
g = df.groupby('ID')['date_int']
first,last = g.transform('first'),g.transform('last')
(df.assign(multi_index = (first.eq('yes') & last.eq('yes'))
.map({True:'yes',False:'no'})
.groupby(df['ID']).head(1)))
Output:
ID A index timestamp timestamp2 date_int multi_index
0 1 activity1 1 2021-02-01 12:03:20 yes no
1 1 activity2 2 2021-02-11 12:03:20 no NaN
2 1 activity3 3 2021-11-23 11:46:40 no NaN
3 1 activity4 4 2021-11-24 11:46:40 no NaN
4 1 activity5 5 2021-11-25 11:46:40 no NaN
5 1 activity6 6 2021-11-26 11:46:40 no NaN
6 2 activity7 1 2021-03-01 12:03:20 yes yes
7 2 activity8 2 2021-03-11 12:03:20 no NaN
8 2 activity9 3 2021-12-23 11:46:40 no NaN
9 2 activity10 4 2021-12-27 11:46:40 no NaN
10 2 activity11 5 2021-12-28 11:46:40 no NaN
11 2 activity12 6 2021-12-29 11:46:40 yes NaN